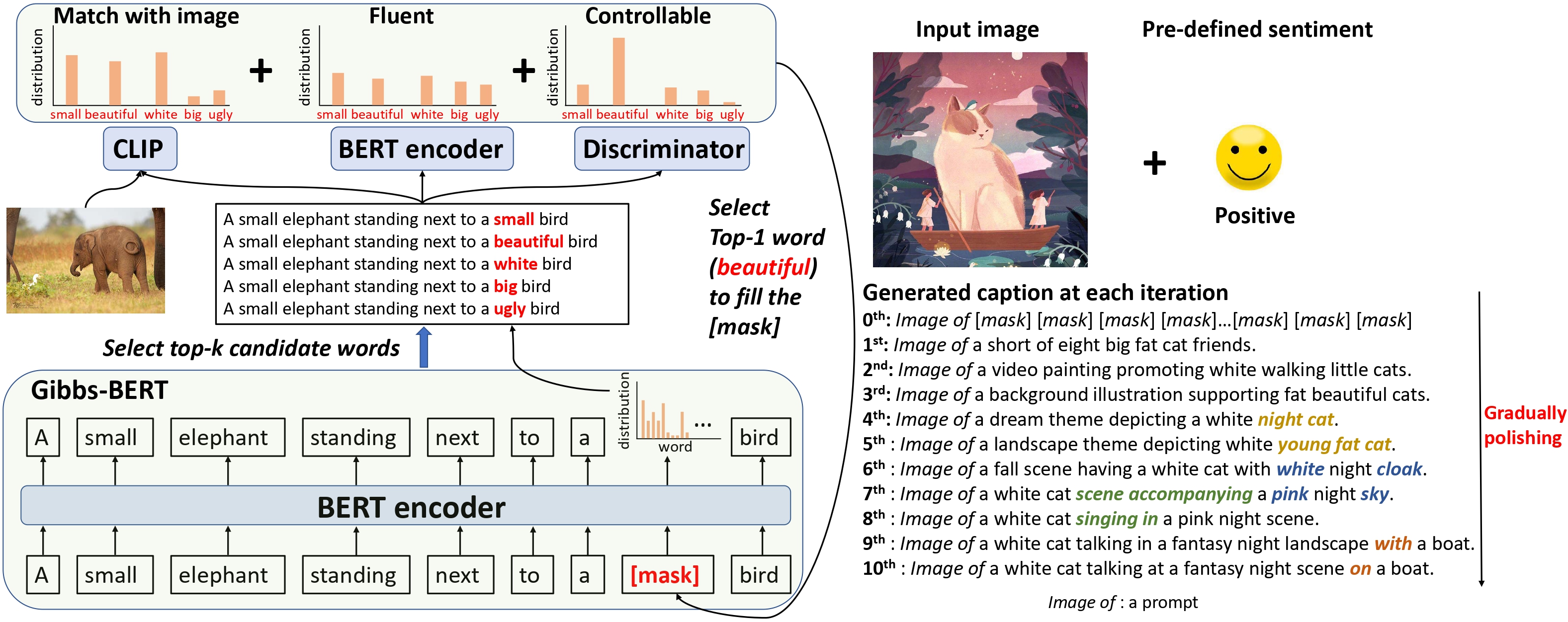
ConZIC: Controllable Zero-shot Image Captioning by Sampling-Based Polishing
Zero-shot capability has been considered as a new revolution of deep learning, letting machines work on tasks without curated training data. As a good start and the only existing outcome of zero-shot image captioning (IC), ZeroCap abandons supervised training and sequentially searches every word in the caption using the knowledge of large-scale pretrained models. Though effective, its autoregressive generation and gradient-directed searching mechanism limit the diversity of captions and inference speed, respectively. Moreover, ZeroCap does not consider the controllability issue of zero-shot IC. To move forward, we propose a framework for Controllable Zero-shot IC, named ConZIC. The core of ConZIC is a novel sampling-based non-autoregressive language model named GibbsBERT, which can generate and continuously polish every word. Extensive quantitative and qualitative results demonstrate the superior performance of our proposed ConZIC for both zero-shot IC and controllable zero-shot IC. Especially, ConZIC achieves about 5x faster generation speed than ZeroCap, and about 1.5x higher diversity scores, with accurate generation given different control signals.
PDF Abstract CVPR 2023 PDF CVPR 2023 Abstract Colab
Colab
 Spaces
Spaces



 MS COCO
MS COCO
 SentiCap
SentiCap
 SketchyCOCO
SketchyCOCO
