CoQA: A Conversational Question Answering Challenge
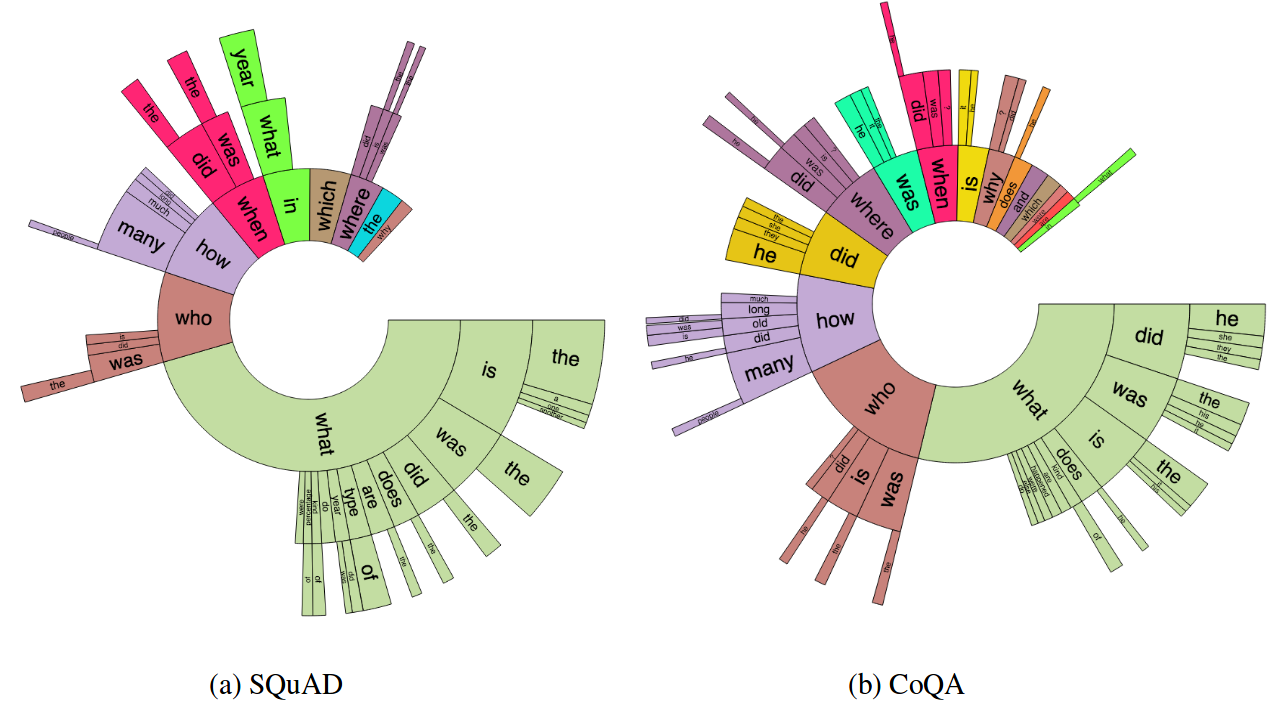
Humans gather information by engaging in conversations involving a series of interconnected questions and answers. For machines to assist in information gathering, it is therefore essential to enable them to answer conversational questions. We introduce CoQA, a novel dataset for building Conversational Question Answering systems. Our dataset contains 127k questions with answers, obtained from 8k conversations about text passages from seven diverse domains. The questions are conversational, and the answers are free-form text with their corresponding evidence highlighted in the passage. We analyze CoQA in depth and show that conversational questions have challenging phenomena not present in existing reading comprehension datasets, e.g., coreference and pragmatic reasoning. We evaluate strong conversational and reading comprehension models on CoQA. The best system obtains an F1 score of 65.4%, which is 23.4 points behind human performance (88.8%), indicating there is ample room for improvement. We launch CoQA as a challenge to the community at http://stanfordnlp.github.io/coqa/
PDF Abstract TACL 2019 PDF TACL 2019 Abstract




 CoQA
CoQA
 SQuAD
SQuAD
 MS MARCO
MS MARCO
 NarrativeQA
NarrativeQA
 MCTest
MCTest

