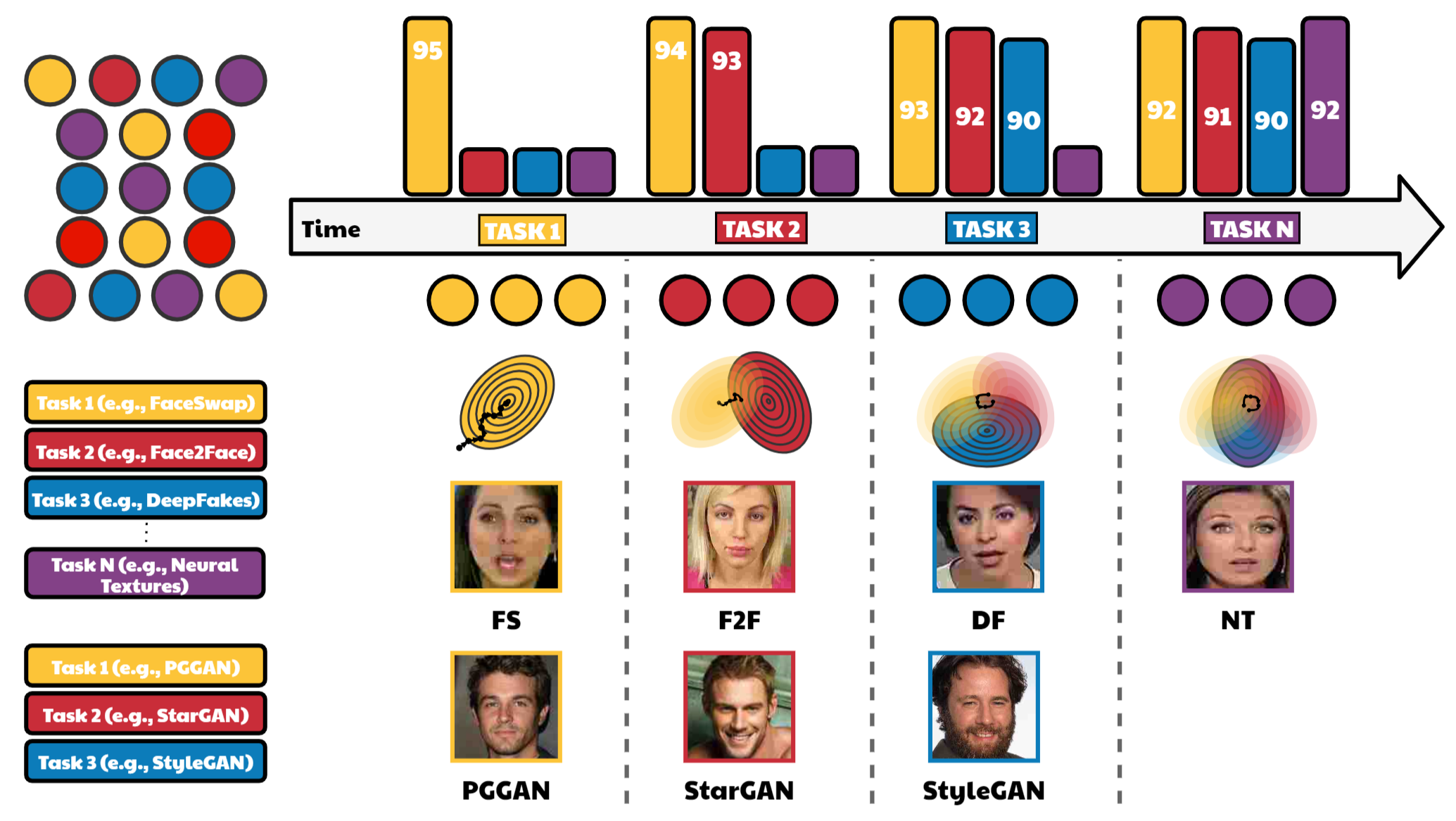
CoReD: Generalizing Fake Media Detection with Continual Representation using Distillation
Over the last few decades, artificial intelligence research has made tremendous strides, but it still heavily relies on fixed datasets in stationary environments. Continual learning is a growing field of research that examines how AI systems can learn sequentially from a continuous stream of linked data in the same way that biological systems do. Simultaneously, fake media such as deepfakes and synthetic face images have emerged as significant to current multimedia technologies. Recently, numerous method has been proposed which can detect deepfakes with high accuracy. However, they suffer significantly due to their reliance on fixed datasets in limited evaluation settings. Therefore, in this work, we apply continuous learning to neural networks' learning dynamics, emphasizing its potential to increase data efficiency significantly. We propose Continual Representation using Distillation (CoReD) method that employs the concept of Continual Learning (CL), Representation Learning (RL), and Knowledge Distillation (KD). We design CoReD to perform sequential domain adaptation tasks on new deepfake and GAN-generated synthetic face datasets, while effectively minimizing the catastrophic forgetting in a teacher-student model setting. Our extensive experimental results demonstrate that our method is efficient at domain adaptation to detect low-quality deepfakes videos and GAN-generated images from several datasets, outperforming the-state-of-art baseline methods.
PDF Abstract





 CelebA
CelebA
 FaceForensics++
FaceForensics++
 Celeb-DF
Celeb-DF
