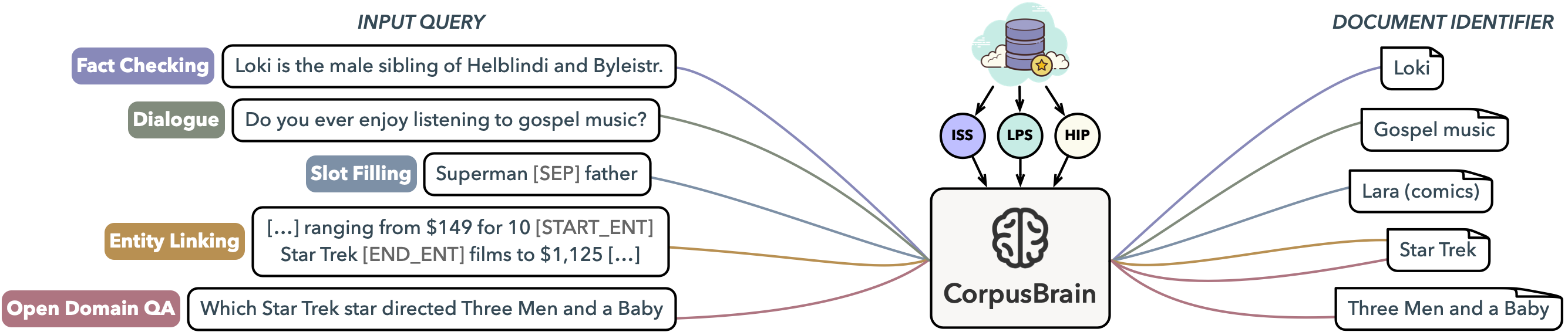
CorpusBrain: Pre-train a Generative Retrieval Model for Knowledge-Intensive Language Tasks
Knowledge-intensive language tasks (KILT) usually require a large body of information to provide correct answers. A popular paradigm to solve this problem is to combine a search system with a machine reader, where the former retrieves supporting evidences and the latter examines them to produce answers. Recently, the reader component has witnessed significant advances with the help of large-scale pre-trained generative models. Meanwhile most existing solutions in the search component rely on the traditional ``index-retrieve-then-rank'' pipeline, which suffers from large memory footprint and difficulty in end-to-end optimization. Inspired by recent efforts in constructing model-based IR models, we propose to replace the traditional multi-step search pipeline with a novel single-step generative model, which can dramatically simplify the search process and be optimized in an end-to-end manner. We show that a strong generative retrieval model can be learned with a set of adequately designed pre-training tasks, and be adopted to improve a variety of downstream KILT tasks with further fine-tuning. We name the pre-trained generative retrieval model as CorpusBrain as all information about the corpus is encoded in its parameters without the need of constructing additional index. Empirical results show that CorpusBrain can significantly outperform strong baselines for the retrieval task on the KILT benchmark and establish new state-of-the-art downstream performances. We also show that CorpusBrain works well under zero- and low-resource settings.
PDF Abstract

 Natural Questions
Natural Questions
 ELI5
ELI5
 KILT
KILT
