Cross-modal Contrastive Learning for Speech Translation
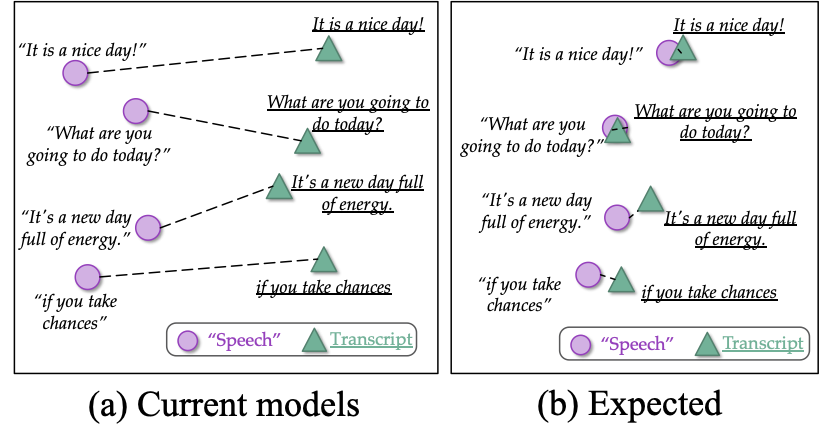
How can we learn unified representations for spoken utterances and their written text? Learning similar representations for semantically similar speech and text is important for speech translation. To this end, we propose ConST, a cross-modal contrastive learning method for end-to-end speech-to-text translation. We evaluate ConST and a variety of previous baselines on a popular benchmark MuST-C. Experiments show that the proposed ConST consistently outperforms the previous methods on, and achieves an average BLEU of 29.4. The analysis further verifies that ConST indeed closes the representation gap of different modalities -- its learned representation improves the accuracy of cross-modal speech-text retrieval from 4% to 88%. Code and models are available at https://github.com/ReneeYe/ConST.
PDF Abstract NAACL 2022 PDF NAACL 2022 Abstract Spaces
Spaces



 LibriSpeech
LibriSpeech
 OpenSubtitles
OpenSubtitles
 MuST-C
MuST-C
