Cross-modal Prototype Driven Network for Radiology Report Generation
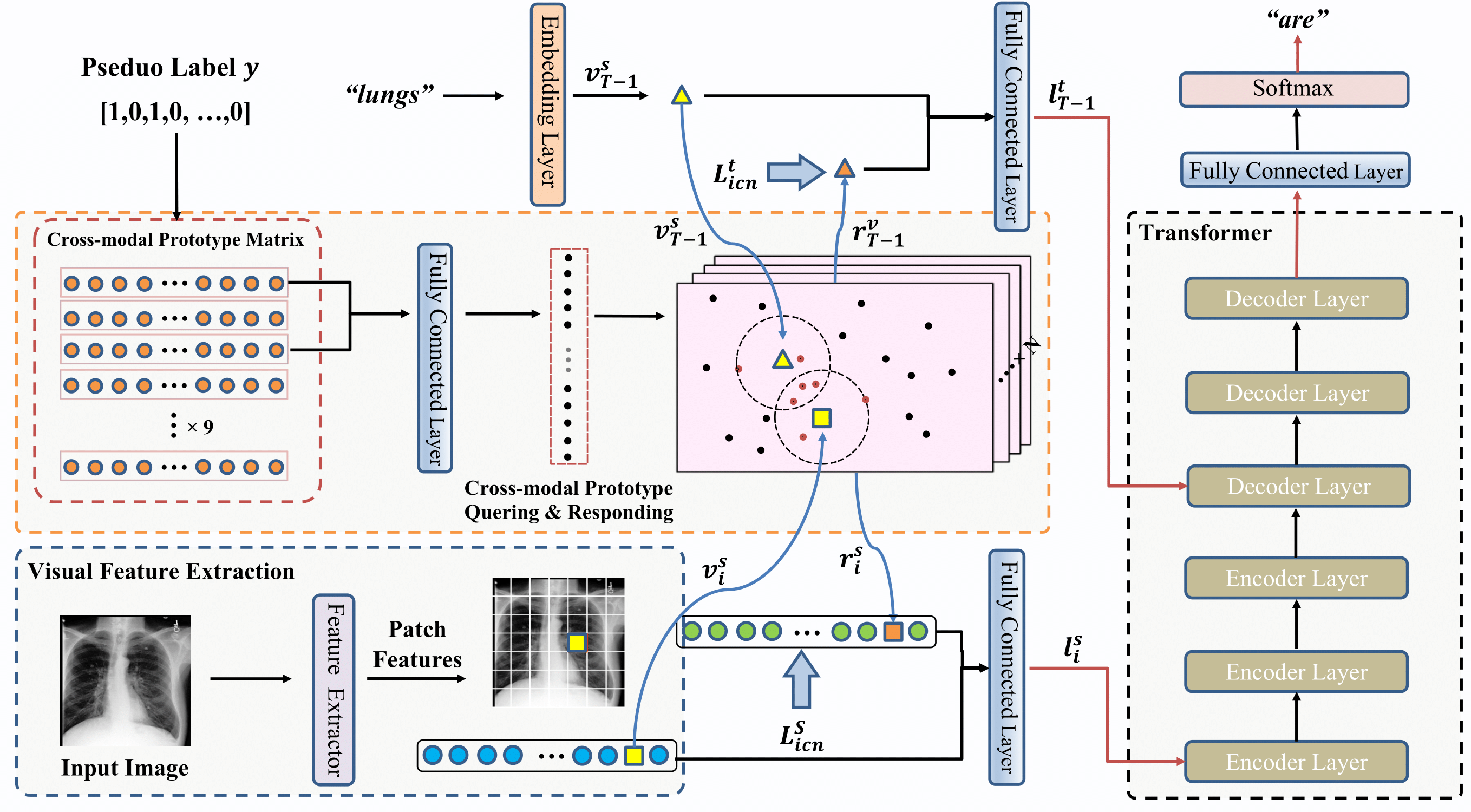
Radiology report generation (RRG) aims to describe automatically a radiology image with human-like language and could potentially support the work of radiologists, reducing the burden of manual reporting. Previous approaches often adopt an encoder-decoder architecture and focus on single-modal feature learning, while few studies explore cross-modal feature interaction. Here we propose a Cross-modal PROtotype driven NETwork (XPRONET) to promote cross-modal pattern learning and exploit it to improve the task of radiology report generation. This is achieved by three well-designed, fully differentiable and complementary modules: a shared cross-modal prototype matrix to record the cross-modal prototypes; a cross-modal prototype network to learn the cross-modal prototypes and embed the cross-modal information into the visual and textual features; and an improved multi-label contrastive loss to enable and enhance multi-label prototype learning. XPRONET obtains substantial improvements on the IU-Xray and MIMIC-CXR benchmarks, where its performance exceeds recent state-of-the-art approaches by a large margin on IU-Xray and comparable performance on MIMIC-CXR.
PDF Abstract
 MIMIC-CXR
MIMIC-CXR
