Cross Modal Transformer: Towards Fast and Robust 3D Object Detection
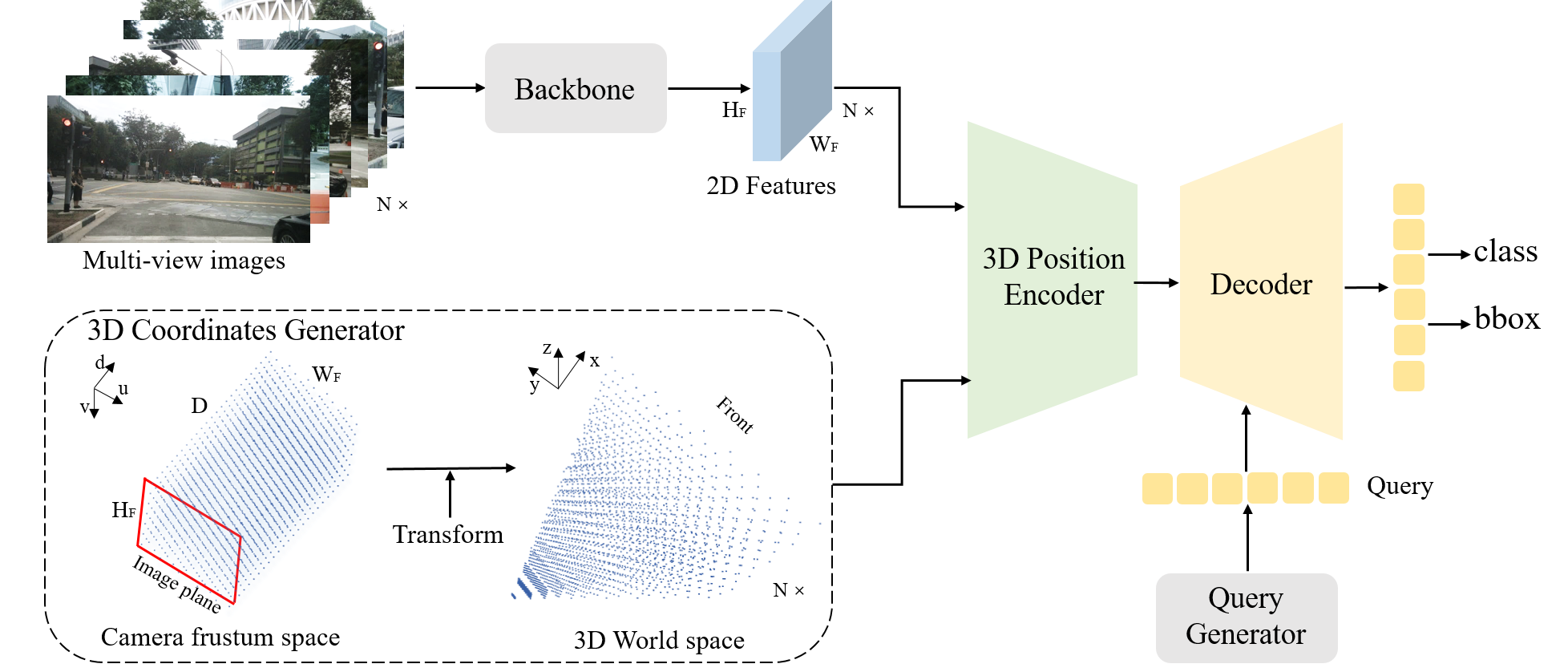
In this paper, we propose a robust 3D detector, named Cross Modal Transformer (CMT), for end-to-end 3D multi-modal detection. Without explicit view transformation, CMT takes the image and point clouds tokens as inputs and directly outputs accurate 3D bounding boxes. The spatial alignment of multi-modal tokens is performed by encoding the 3D points into multi-modal features. The core design of CMT is quite simple while its performance is impressive. It achieves 74.1\% NDS (state-of-the-art with single model) on nuScenes test set while maintaining fast inference speed. Moreover, CMT has a strong robustness even if the LiDAR is missing. Code is released at https://github.com/junjie18/CMT.
PDF Abstract ICCV 2023 PDF ICCV 2023 AbstractCode





Datasets
 nuScenes
nuScenes
 Argoverse 2
Argoverse 2
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
