UniTAB: Unifying Text and Box Outputs for Grounded Vision-Language Modeling
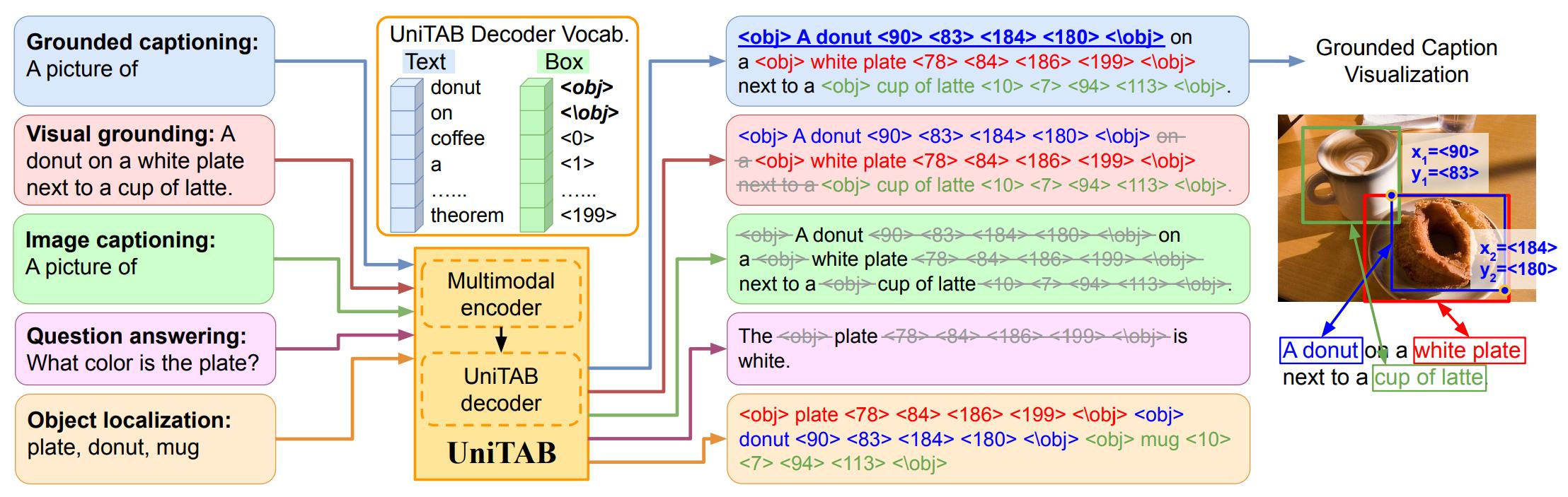
We propose UniTAB that Unifies Text And Box outputs for grounded vision-language (VL) modeling. Grounded VL tasks such as grounded captioning require the model to generate a text description and align predicted words with object regions. To achieve this, models must generate desired text and box outputs together, and meanwhile indicate the alignments between words and boxes. In contrast to existing solutions that use multiple separate modules for different outputs, UniTAB represents both text and box outputs with a shared token sequence, and introduces a special <obj> token to naturally indicate word-box alignments in the sequence. UniTAB thus could provide a more comprehensive and interpretable image description, by freely grounding generated words to object regions. On grounded captioning, UniTAB presents a simpler solution with a single output head, and significantly outperforms state of the art in both grounding and captioning evaluations. On general VL tasks that have different desired output formats (i.e., text, box, or their combination), UniTAB with a single network achieves better or comparable performance than task-specific state of the art. Experiments cover 7 VL benchmarks, including grounded captioning, visual grounding, image captioning, and visual question answering. Furthermore, UniTAB's unified multi-task network and the task-agnostic output sequence design make the model parameter efficient and generalizable to new tasks.
PDF Abstract







 ImageNet
ImageNet
 MS COCO
MS COCO
 Visual Question Answering
Visual Question Answering
 Flickr30K Entities
Flickr30K Entities
