CrossLoc: Scalable Aerial Localization Assisted by Multimodal Synthetic Data
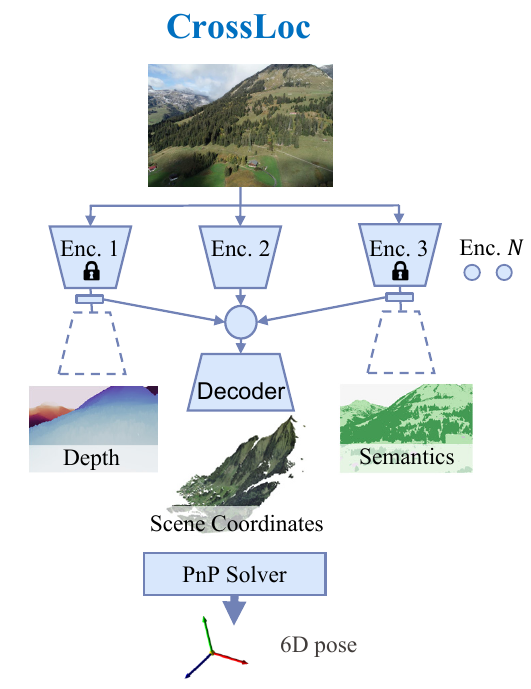
We present a visual localization system that learns to estimate camera poses in the real world with the help of synthetic data. Despite significant progress in recent years, most learning-based approaches to visual localization target at a single domain and require a dense database of geo-tagged images to function well. To mitigate the data scarcity issue and improve the scalability of the neural localization models, we introduce TOPO-DataGen, a versatile synthetic data generation tool that traverses smoothly between the real and virtual world, hinged on the geographic camera viewpoint. New large-scale sim-to-real benchmark datasets are proposed to showcase and evaluate the utility of the said synthetic data. Our experiments reveal that synthetic data generically enhances the neural network performance on real data. Furthermore, we introduce CrossLoc, a cross-modal visual representation learning approach to pose estimation that makes full use of the scene coordinate ground truth via self-supervision. Without any extra data, CrossLoc significantly outperforms the state-of-the-art methods and achieves substantially higher real-data sample efficiency. Our code and datasets are all available at https://crossloc.github.io/.
PDF Abstract CVPR 2022 PDF CVPR 2022 AbstractCode




Datasets
Introduced in the Paper:
 CrossLoc Benchmark Datasets
CrossLoc Benchmark Datasets
