Curriculum Learning Strategies for IR: An Empirical Study on Conversation Response Ranking
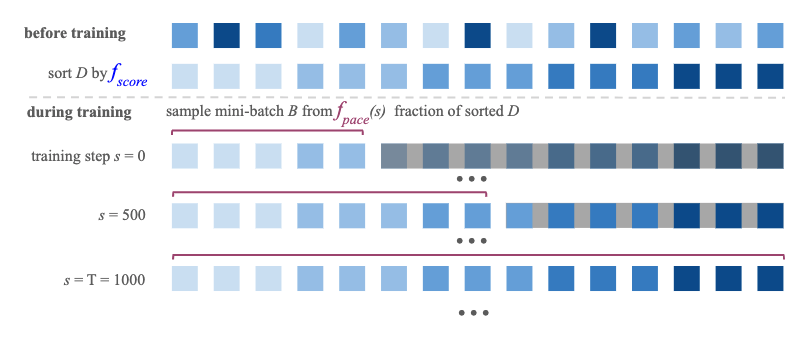
Neural ranking models are traditionally trained on a series of random batches, sampled uniformly from the entire training set. Curriculum learning has recently been shown to improve neural models' effectiveness by sampling batches non-uniformly, going from easy to difficult instances during training. In the context of neural Information Retrieval (IR) curriculum learning has not been explored yet, and so it remains unclear (1) how to measure the difficulty of training instances and (2) how to transition from easy to difficult instances during training. To address both challenges and determine whether curriculum learning is beneficial for neural ranking models, we need large-scale datasets and a retrieval task that allows us to conduct a wide range of experiments. For this purpose, we resort to the task of conversation response ranking: ranking responses given the conversation history. In order to deal with challenge (1), we explore scoring functions to measure the difficulty of conversations based on different input spaces. To address challenge (2) we evaluate different pacing functions, which determine the velocity in which we go from easy to difficult instances. We find that, overall, by just intelligently sorting the training data (i.e., by performing curriculum learning) we can improve the retrieval effectiveness by up to 2%.
PDF Abstract


