DailyTalk: Spoken Dialogue Dataset for Conversational Text-to-Speech
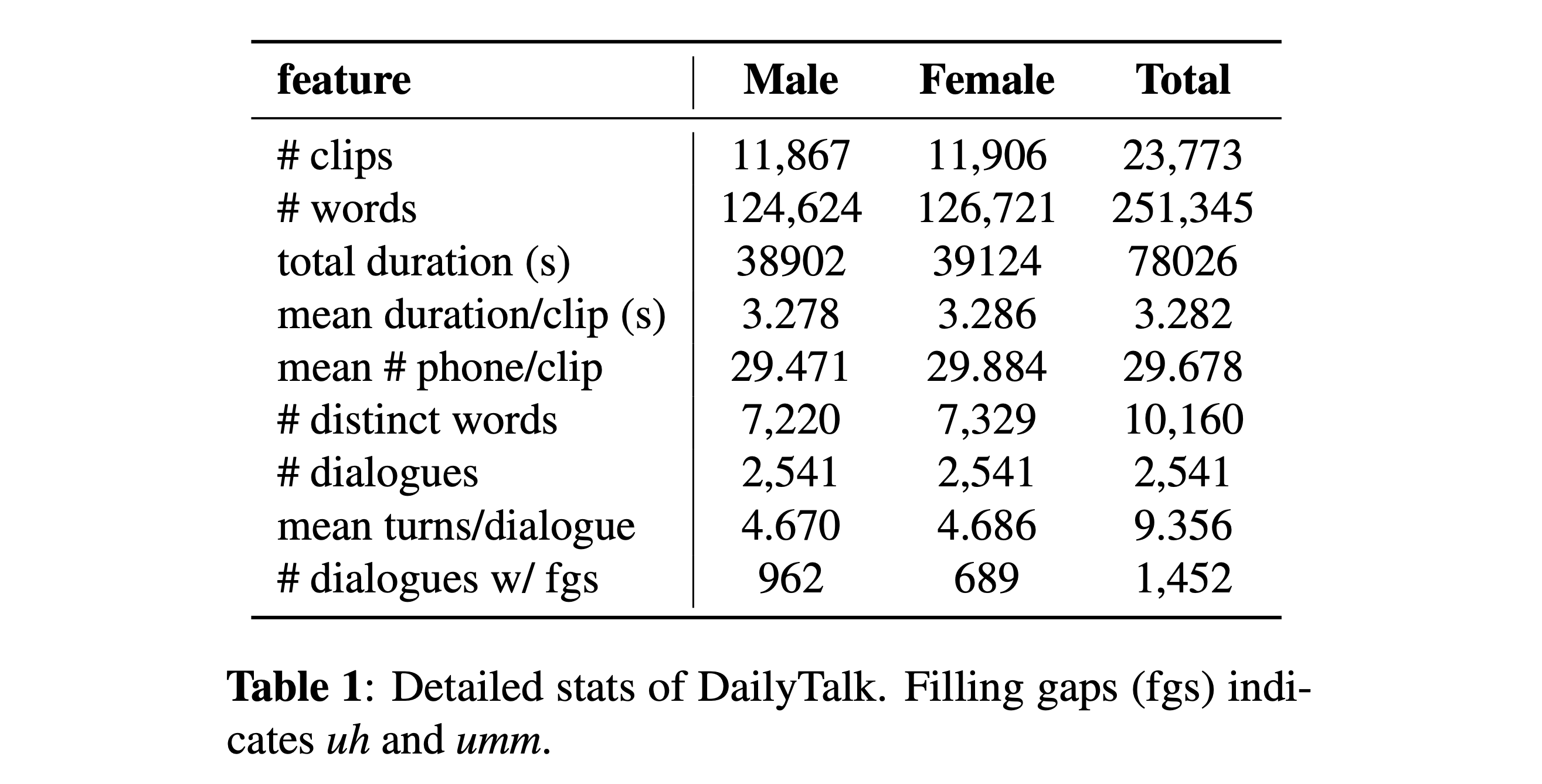
The majority of current Text-to-Speech (TTS) datasets, which are collections of individual utterances, contain few conversational aspects. In this paper, we introduce DailyTalk, a high-quality conversational speech dataset designed for conversational TTS. We sampled, modified, and recorded 2,541 dialogues from the open-domain dialogue dataset DailyDialog inheriting its annotated attributes. On top of our dataset, we extend prior work as our baseline, where a non-autoregressive TTS is conditioned on historical information in a dialogue. From the baseline experiment with both general and our novel metrics, we show that DailyTalk can be used as a general TTS dataset, and more than that, our baseline can represent contextual information from DailyTalk. The DailyTalk dataset and baseline code are freely available for academic use with CC-BY-SA 4.0 license.
PDF Abstract
 DailyDialog
DailyDialog
 LJSpeech
LJSpeech
