DAM: Deliberation, Abandon and Memory Networks for Generating Detailed and Non-repetitive Responses in Visual Dialogue
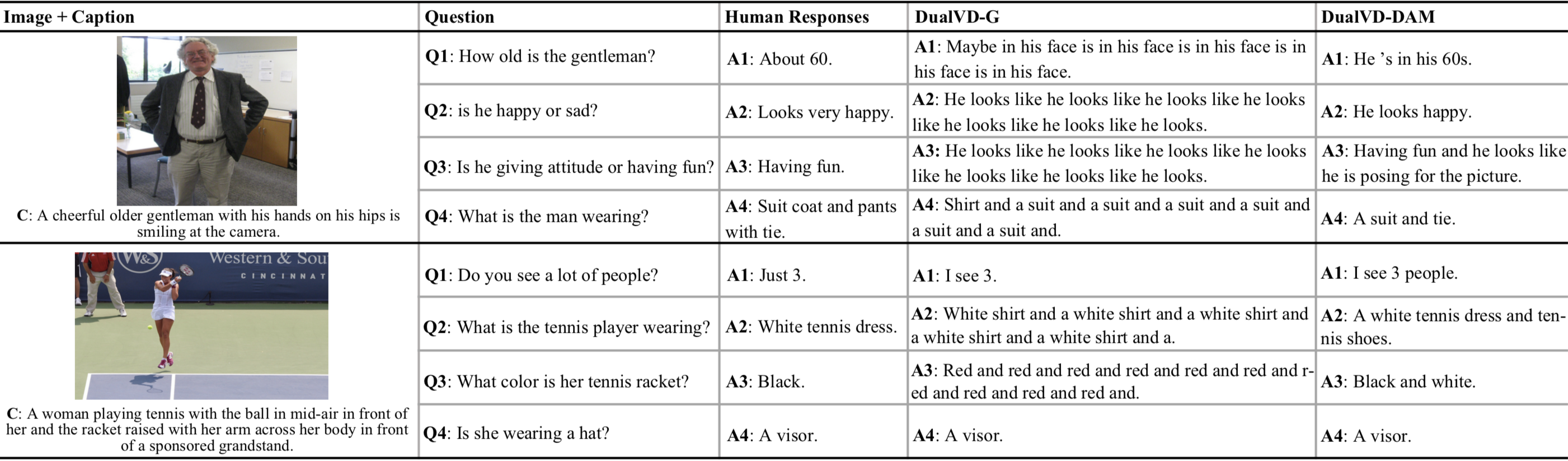
Visual Dialogue task requires an agent to be engaged in a conversation with human about an image. The ability of generating detailed and non-repetitive responses is crucial for the agent to achieve human-like conversation. In this paper, we propose a novel generative decoding architecture to generate high-quality responses, which moves away from decoding the whole encoded semantics towards the design that advocates both transparency and flexibility. In this architecture, word generation is decomposed into a series of attention-based information selection steps, performed by the novel recurrent Deliberation, Abandon and Memory (DAM) module. Each DAM module performs an adaptive combination of the response-level semantics captured from the encoder and the word-level semantics specifically selected for generating each word. Therefore, the responses contain more detailed and non-repetitive descriptions while maintaining the semantic accuracy. Furthermore, DAM is flexible to cooperate with existing visual dialogue encoders and adaptive to the encoder structures by constraining the information selection mode in DAM. We apply DAM to three typical encoders and verify the performance on the VisDial v1.0 dataset. Experimental results show that the proposed models achieve new state-of-the-art performance with high-quality responses. The code is available at https://github.com/JXZe/DAM.
PDF Abstract

 VisDial
VisDial
