Data-Efficient Finetuning Using Cross-Task Nearest Neighbors
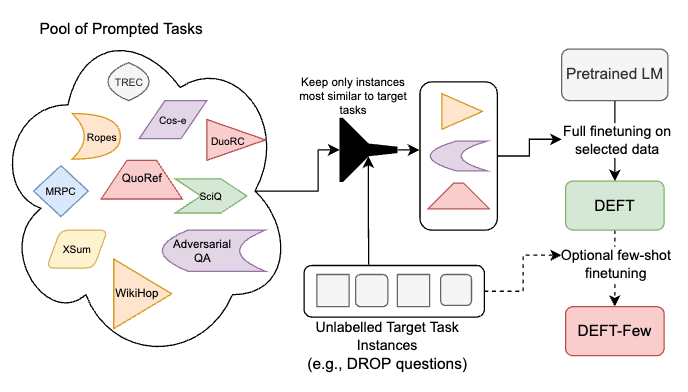
Obtaining labeled data to train a model for a task of interest is often expensive. Prior work shows training models on multitask data augmented with task descriptions (prompts) effectively transfers knowledge to new tasks. Towards efficiently building task-specific models, we assume access to a small number (32-1000) of unlabeled target-task examples and use those to retrieve the most similar labeled examples from a large pool of multitask data augmented with prompts. Compared to the current practice of finetuning models on uniformly sampled prompted multitask data (e.g.: FLAN, T0), our approach of finetuning on cross-task nearest neighbors is significantly more data-efficient. Using only 2% of the data from the P3 pool without any labeled target-task data, our models outperform strong baselines trained on all available data by 3-30% on 12 out of 14 datasets representing held-out tasks including legal and scientific document QA. Similarly, models trained on cross-task nearest neighbors from SuperNaturalInstructions, representing about 5% of the pool, obtain comparable performance to state-of-the-art models on 12 held-out tasks from that pool. Moreover, the models produced by our approach also provide a better initialization than single multitask finetuned models for few-shot finetuning on target-task data, as shown by a 2-23% relative improvement over few-shot finetuned T0-3B models on 8 datasets.
PDF Abstract
 HellaSwag
HellaSwag
 WinoGrande
WinoGrande
 WSC
WSC
 DROP
DROP
 COPA
COPA
 ANLI
ANLI
 QASPER
QASPER
