Data Readiness for Natural Language Processing
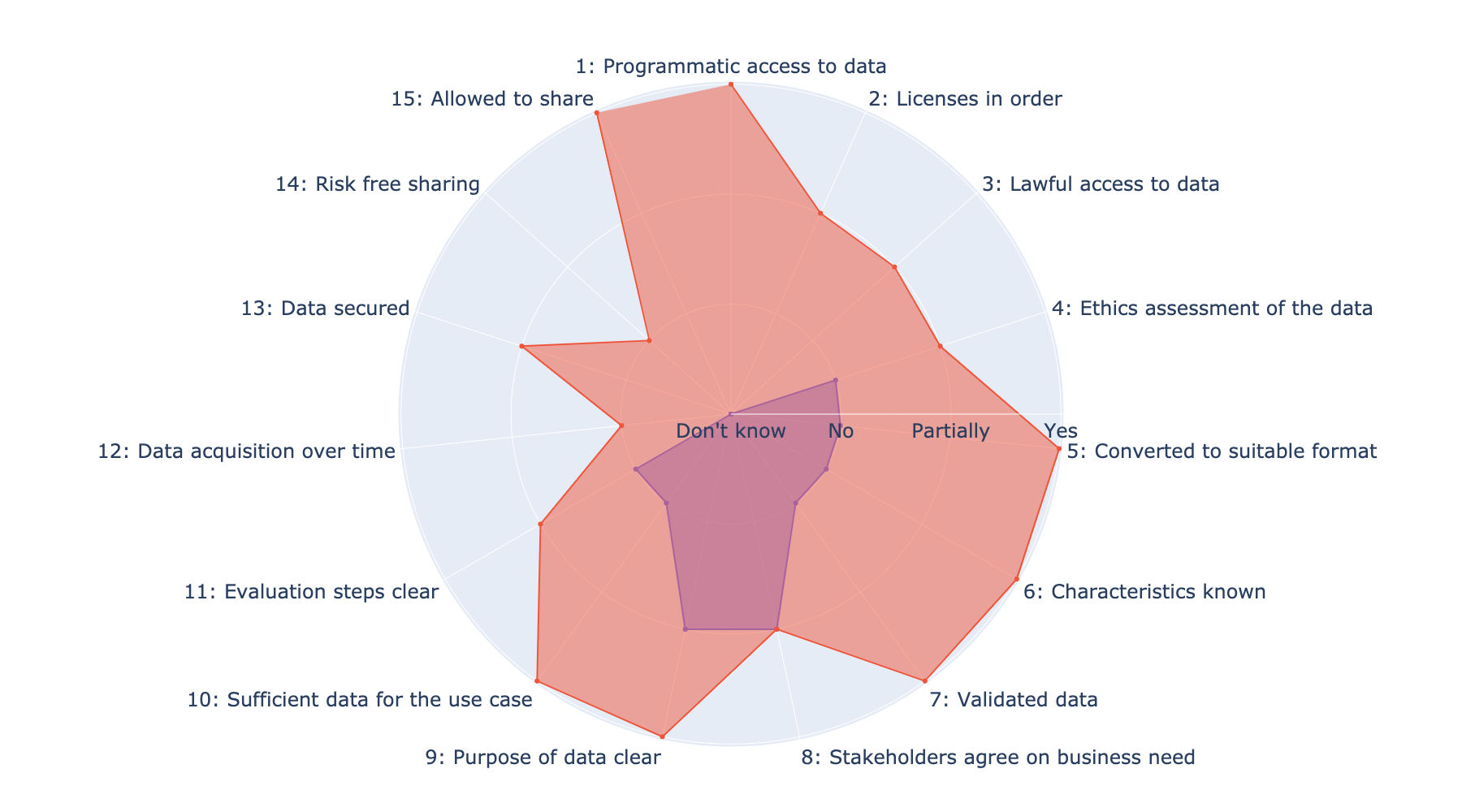
This document concerns data readiness in the context of machine learning and Natural Language Processing. It describes how an organization may proceed to identify, make available, validate, and prepare data to facilitate automated analysis methods. The contents of the document is based on the practical challenges and frequently asked questions we have encountered in our work as an applied research institute with helping organizations and companies, both in the public and private sectors, to use data in their business processes.
PDF Abstract
Datasets
Add Datasets
introduced or used in this paper
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
