Decoupling Zero-Shot Semantic Segmentation
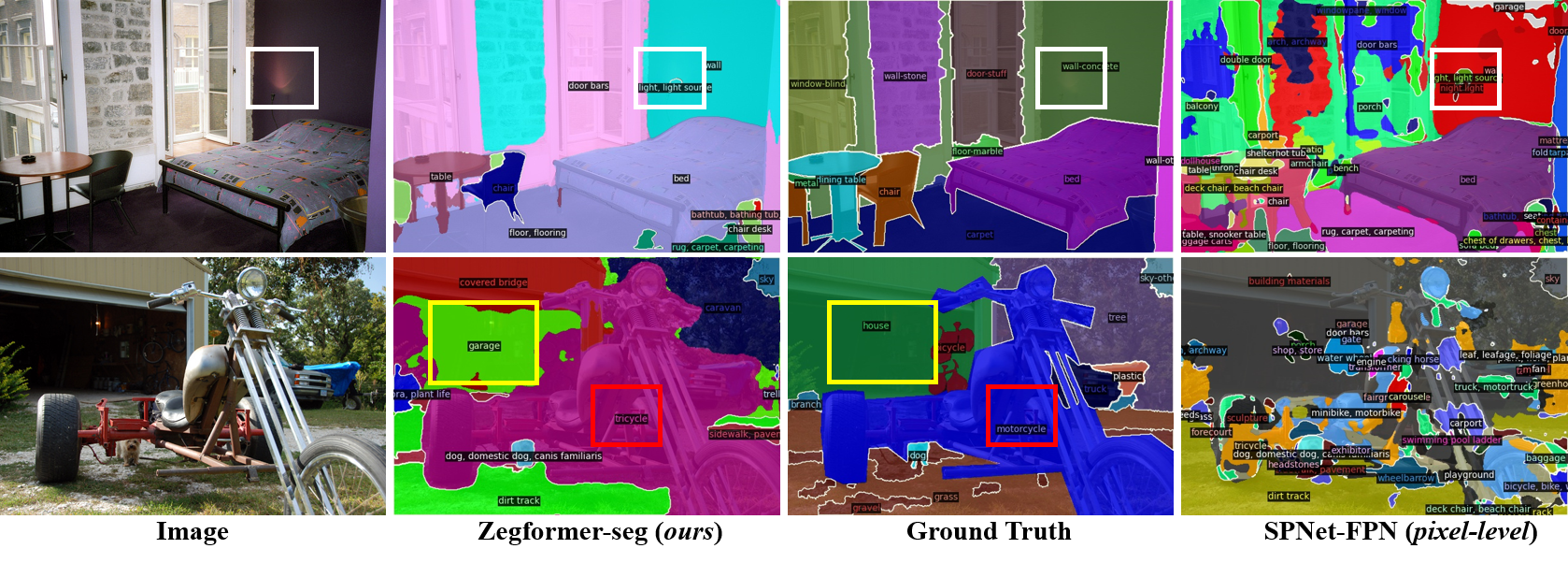
Zero-shot semantic segmentation (ZS3) aims to segment the novel categories that have not been seen in the training. Existing works formulate ZS3 as a pixel-level zeroshot classification problem, and transfer semantic knowledge from seen classes to unseen ones with the help of language models pre-trained only with texts. While simple, the pixel-level ZS3 formulation shows the limited capability to integrate vision-language models that are often pre-trained with image-text pairs and currently demonstrate great potential for vision tasks. Inspired by the observation that humans often perform segment-level semantic labeling, we propose to decouple the ZS3 into two sub-tasks: 1) a classagnostic grouping task to group the pixels into segments. 2) a zero-shot classification task on segments. The former task does not involve category information and can be directly transferred to group pixels for unseen classes. The latter task performs at segment-level and provides a natural way to leverage large-scale vision-language models pre-trained with image-text pairs (e.g. CLIP) for ZS3. Based on the decoupling formulation, we propose a simple and effective zero-shot semantic segmentation model, called ZegFormer, which outperforms the previous methods on ZS3 standard benchmarks by large margins, e.g., 22 points on the PASCAL VOC and 3 points on the COCO-Stuff in terms of mIoU for unseen classes. Code will be released at https://github.com/dingjiansw101/ZegFormer.
PDF Abstract CVPR 2022 PDF CVPR 2022 Abstract



 ADE20K
ADE20K
 COCO-Stuff
COCO-Stuff
 PASCAL VOC
PASCAL VOC

