Deep Extreme Cut: From Extreme Points to Object Segmentation
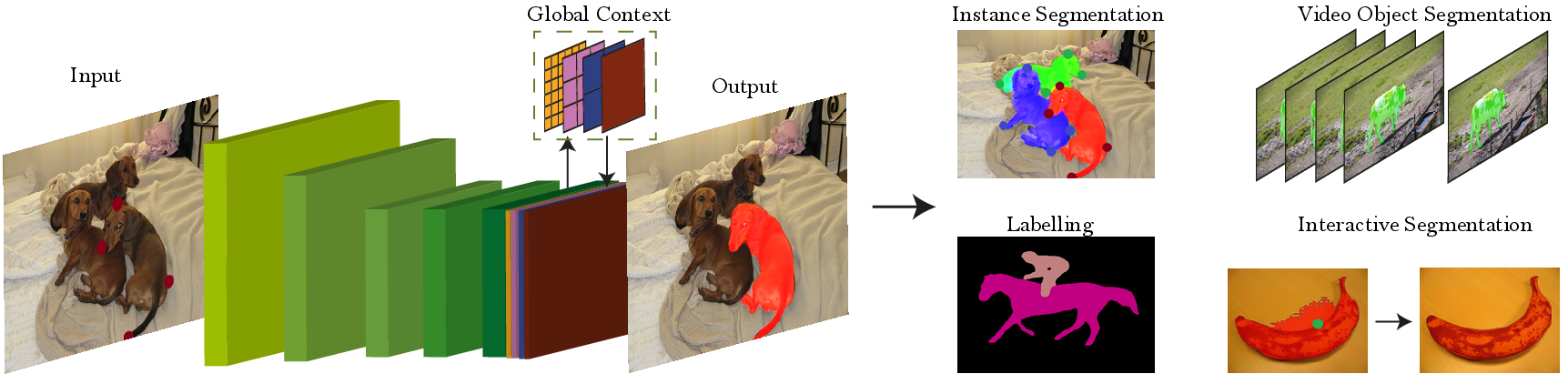
This paper explores the use of extreme points in an object (left-most, right-most, top, bottom pixels) as input to obtain precise object segmentation for images and videos. We do so by adding an extra channel to the image in the input of a convolutional neural network (CNN), which contains a Gaussian centered in each of the extreme points. The CNN learns to transform this information into a segmentation of an object that matches those extreme points. We demonstrate the usefulness of this approach for guided segmentation (grabcut-style), interactive segmentation, video object segmentation, and dense segmentation annotation. We show that we obtain the most precise results to date, also with less user input, in an extensive and varied selection of benchmarks and datasets. All our models and code are publicly available on http://www.vision.ee.ethz.ch/~cvlsegmentation/dextr/.
PDF Abstract CVPR 2018 PDF CVPR 2018 Abstract





 MS COCO
MS COCO
 DAVIS
DAVIS
 DAVIS 2017
DAVIS 2017
 DAVIS 2016
DAVIS 2016
 SBD
SBD
