Deep Extreme Multi-label Learning
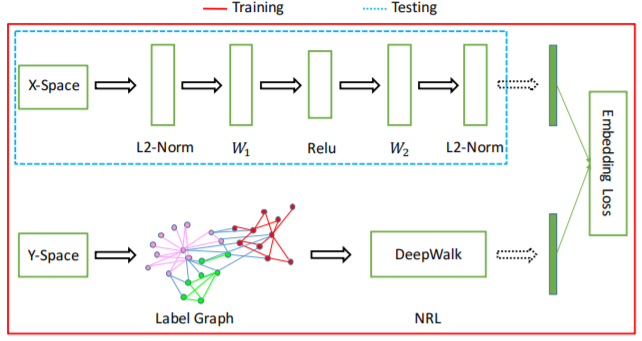
Extreme multi-label learning (XML) or classification has been a practical and important problem since the boom of big data. The main challenge lies in the exponential label space which involves $2^L$ possible label sets especially when the label dimension $L$ is huge, e.g., in millions for Wikipedia labels. This paper is motivated to better explore the label space by originally establishing an explicit label graph. In the meanwhile, deep learning has been widely studied and used in various classification problems including multi-label classification, however it has not been properly introduced to XML, where the label space can be as large as in millions. In this paper, we propose a practical deep embedding method for extreme multi-label classification, which harvests the ideas of non-linear embedding and graph priors-based label space modeling simultaneously. Extensive experiments on public datasets for XML show that our method performs competitive against state-of-the-art result.
PDF Abstract




 Delicious
Delicious
