
Deep Matching Prior: Test-Time Optimization for Dense Correspondence
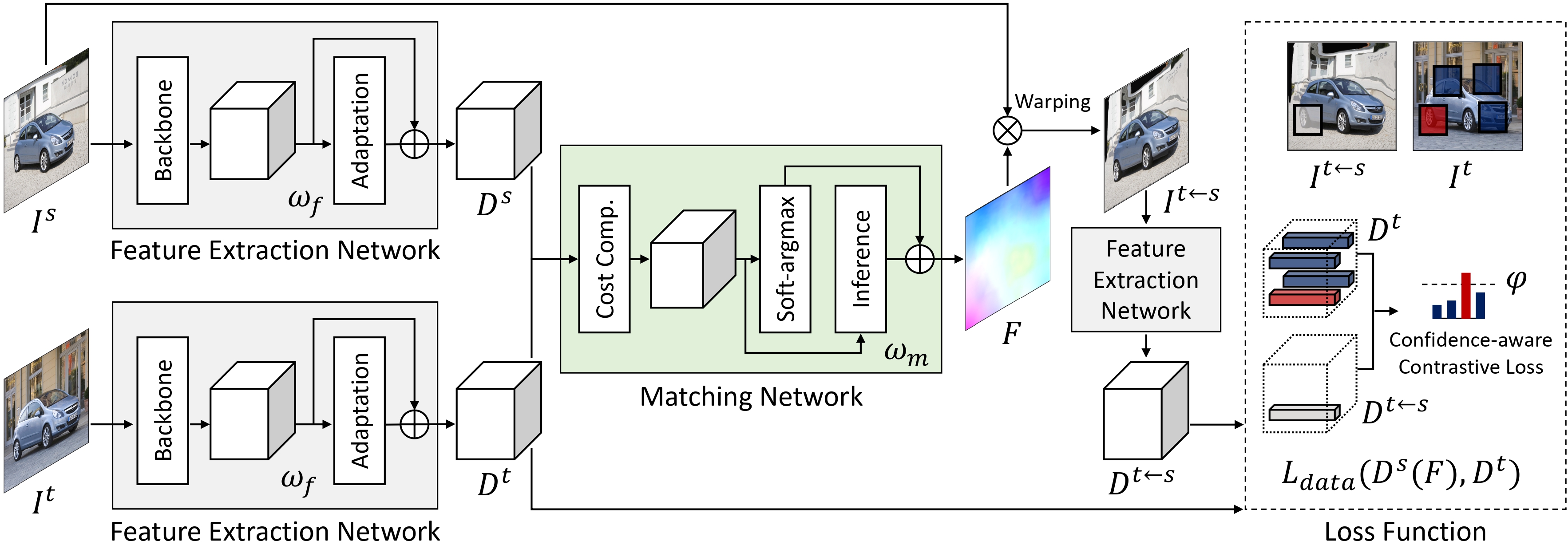
Conventional techniques to establish dense correspondences across visually or semantically similar images focused on designing a task-specific matching prior, which is difficult to model. To overcome this, recent learning-based methods have attempted to learn a good matching prior within a model itself on large training data. The performance improvement was apparent, but the need for sufficient training data and intensive learning hinders their applicability. Moreover, using the fixed model at test time does not account for the fact that a pair of images may require their own prior, thus providing limited performance and poor generalization to unseen images. In this paper, we show that an image pair-specific prior can be captured by solely optimizing the untrained matching networks on an input pair of images. Tailored for such test-time optimization for dense correspondence, we present a residual matching network and a confidence-aware contrastive loss to guarantee a meaningful convergence. Experiments demonstrate that our framework, dubbed Deep Matching Prior (DMP), is competitive, or even outperforms, against the latest learning-based methods on several benchmarks for geometric matching and semantic matching, even though it requires neither large training data nor intensive learning. With the networks pre-trained, DMP attains state-of-the-art performance on all benchmarks.
PDF Abstract ICCV 2021 PDF ICCV 2021 Abstract
 ImageNet
ImageNet
 HPatches
HPatches
 ETH3D
ETH3D
 PF-PASCAL
PF-PASCAL
Results from the Paper
![]() Ranked #1 on
Dense Pixel Correspondence Estimation
on HPatches
(using extra training data)
Ranked #1 on
Dense Pixel Correspondence Estimation
on HPatches
(using extra training data)
