Deep Multimodal Transfer-Learned Regression in Data-Poor Domains
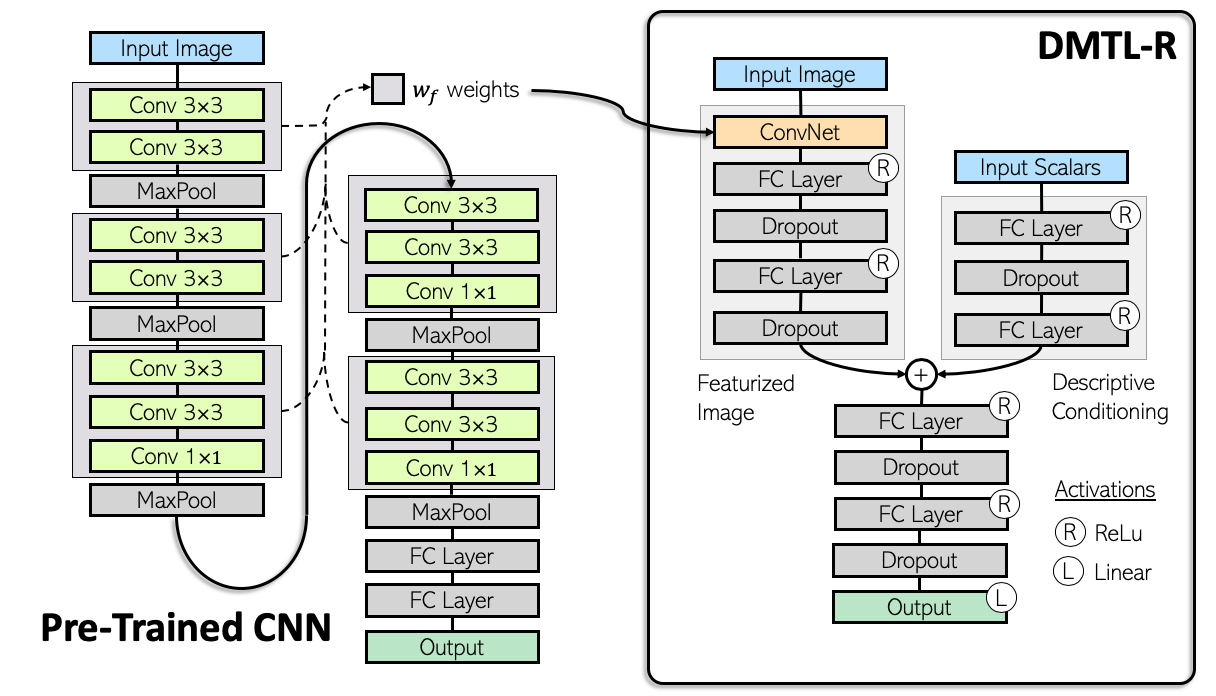
In many real-world applications of deep learning, estimation of a target may rely on various types of input data modes, such as audio-video, image-text, etc. This task can be further complicated by a lack of sufficient data. Here we propose a Deep Multimodal Transfer-Learned Regressor (DMTL-R) for multimodal learning of image and feature data in a deep regression architecture effective at predicting target parameters in data-poor domains. Our model is capable of fine-tuning a given set of pre-trained CNN weights on a small amount of training image data, while simultaneously conditioning on feature information from a complimentary data mode during network training, yielding more accurate single-target or multi-target regression than can be achieved using the images or the features alone. We present results using phase-field simulation microstructure images with an accompanying set of physical features, using pre-trained weights from various well-known CNN architectures, which demonstrate the efficacy of the proposed multimodal approach.
PDF Abstract

