Deep TEN: Texture Encoding Network
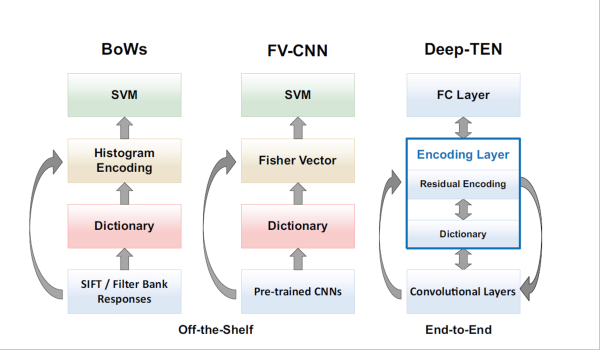
We propose a Deep Texture Encoding Network (Deep-TEN) with a novel Encoding Layer integrated on top of convolutional layers, which ports the entire dictionary learning and encoding pipeline into a single model. Current methods build from distinct components, using standard encoders with separate off-the-shelf features such as SIFT descriptors or pre-trained CNN features for material recognition. Our new approach provides an end-to-end learning framework, where the inherent visual vocabularies are learned directly from the loss function. The features, dictionaries and the encoding representation for the classifier are all learned simultaneously. The representation is orderless and therefore is particularly useful for material and texture recognition. The Encoding Layer generalizes robust residual encoders such as VLAD and Fisher Vectors, and has the property of discarding domain specific information which makes the learned convolutional features easier to transfer. Additionally, joint training using multiple datasets of varied sizes and class labels is supported resulting in increased recognition performance. The experimental results show superior performance as compared to state-of-the-art methods using gold-standard databases such as MINC-2500, Flickr Material Database, KTH-TIPS-2b, and two recent databases 4D-Light-Field-Material and GTOS. The source code for the complete system are publicly available.
PDF Abstract CVPR 2017 PDF CVPR 2017 Abstract


 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 Caltech-101
Caltech-101
 MINC
MINC
