Deep Video Super-Resolution Network Using Dynamic Upsampling Filters Without Explicit Motion Compensation
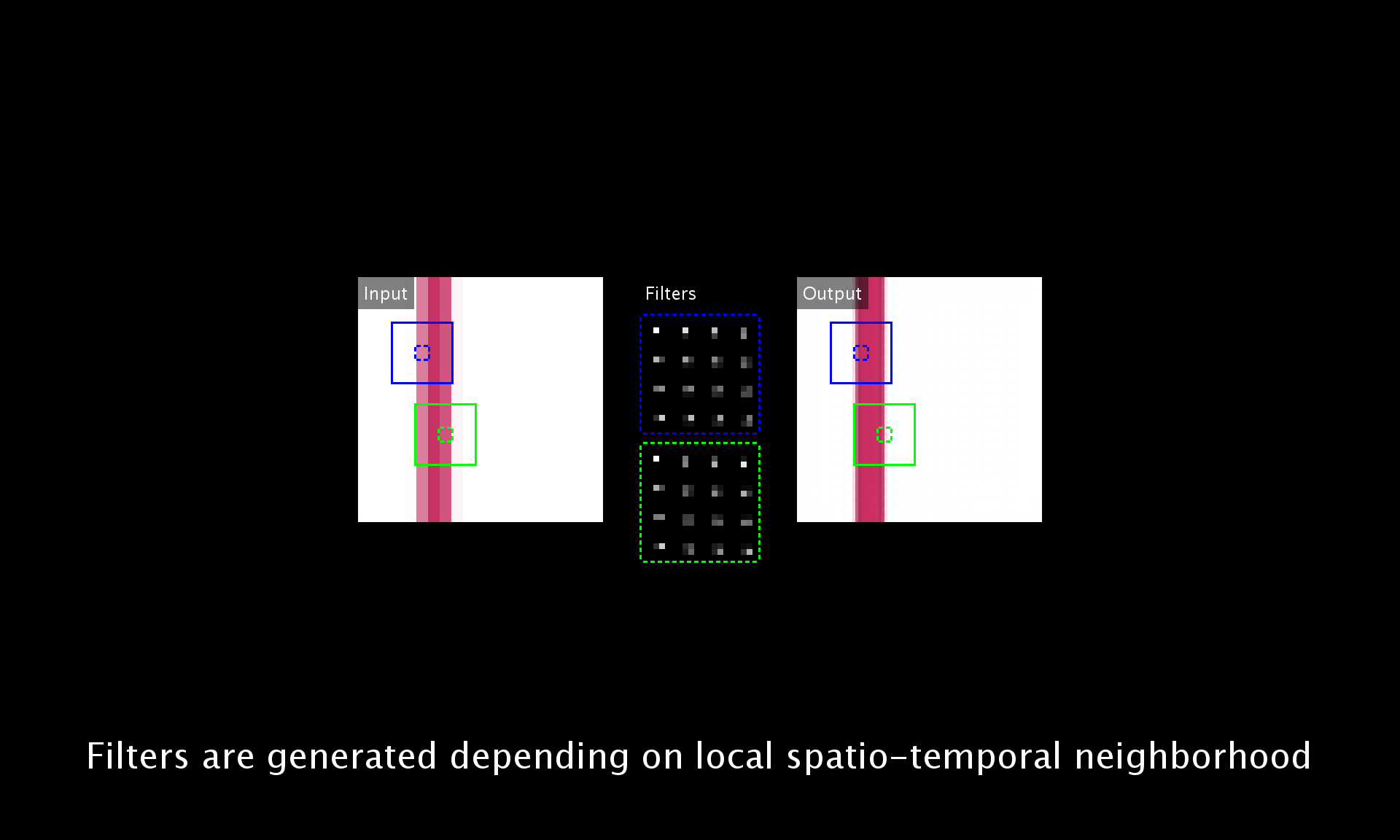
Video super-resolution (VSR) has become even more important recently to provide high resolution (HR) contents for ultra high definition displays. While many deep learning based VSR methods have been proposed, most of them rely heavily on the accuracy of motion estimation and compensation. We introduce a fundamentally different framework for VSR in this paper. We propose a novel end-to-end deep neural network that generates dynamic upsampling filters and a residual image, which are computed depending on the local spatio-temporal neighborhood of each pixel to avoid explicit motion compensation. With our approach, an HR image is reconstructed directly from the input image using the dynamic upsampling filters, and the fine details are added through the computed residual. Our network with the help of a new data augmentation technique can generate much sharper HR videos with temporal consistency, compared with the previous methods. We also provide analysis of our network through extensive experiments to show how the network deals with motions implicitly.
PDF AbstractCode





 MSU Video Super Resolution Benchmark: Detail Restoration
MSU Video Super Resolution Benchmark: Detail Restoration
Results from the Paper

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Video Super-Resolution | MSU Video Super Resolution Benchmark: Detail Restoration | DUF-16L | Subjective score | 5.124 | # 18 | |
| ERQAv1.0 | 0.641 | # 22 | ||||
| QRCRv1.0 | 0.549 | # 14 | ||||
| SSIM | 0.828 | # 19 | ||||
| PSNR | 24.606 | # 28 | ||||
| FPS | 0.605 | # 20 | ||||
| 1 - LPIPS | 0.868 | # 19 | ||||
| Video Super-Resolution | MSU Video Super Resolution Benchmark: Detail Restoration | DUF-28L | Subjective score | 5.324 | # 16 | |
| ERQAv1.0 | 0.645 | # 20 | ||||
| QRCRv1.0 | 0.549 | # 14 | ||||
| SSIM | 0.83 | # 18 | ||||
| PSNR | 25.852 | # 23 | ||||
| FPS | 0.418 | # 23 | ||||
| 1 - LPIPS | 0.87 | # 18 | ||||
| Video Super-Resolution | Vid4 - 4x upscaling | VSR-DUF | PSNR | 27.33 | # 8 | |
| SSIM | 0.8319 | # 6 | ||||
| Video Super-Resolution | Vid4 - 4x upscaling - BD degradation | DUF | PSNR | 27.38 | # 14 | |
| SSIM | 0.8329 | # 15 |
