Deep Visual Template-Free Form Parsing
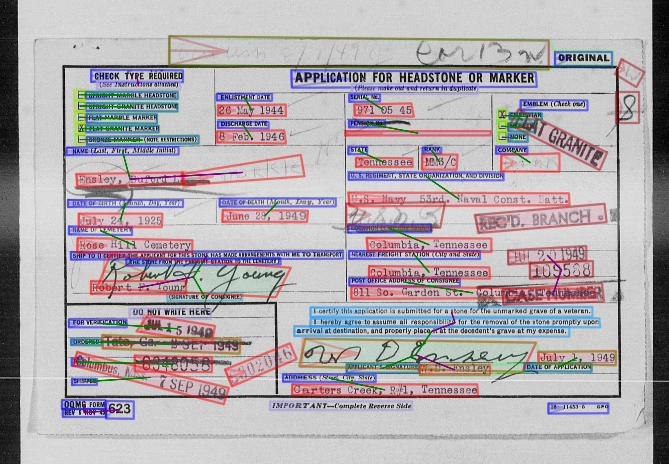
Automatic, template-free extraction of information from form images is challenging due to the variety of form layouts. This is even more challenging for historical forms due to noise and degradation. A crucial part of the extraction process is associating input text with pre-printed labels. We present a learned, template-free solution to detecting pre-printed text and input text/handwriting and predicting pair-wise relationships between them. While previous approaches to this problem have been focused on clean images and clear layouts, we show our approach is effective in the domain of noisy, degraded, and varied form images. We introduce a new dataset of historical form images (late 1800s, early 1900s) for training and validating our approach. Our method uses a convolutional network to detect pre-printed text and input text lines. We pool features from the detection network to classify possible relationships in a language-agnostic way. We show that our proposed pairing method outperforms heuristic rules and that visual features are critical to obtaining high accuracy.
PDF AbstractCode

Tasks
Datasets
Introduced in the Paper:
 NAF
NAF
