Deep ViT Features as Dense Visual Descriptors
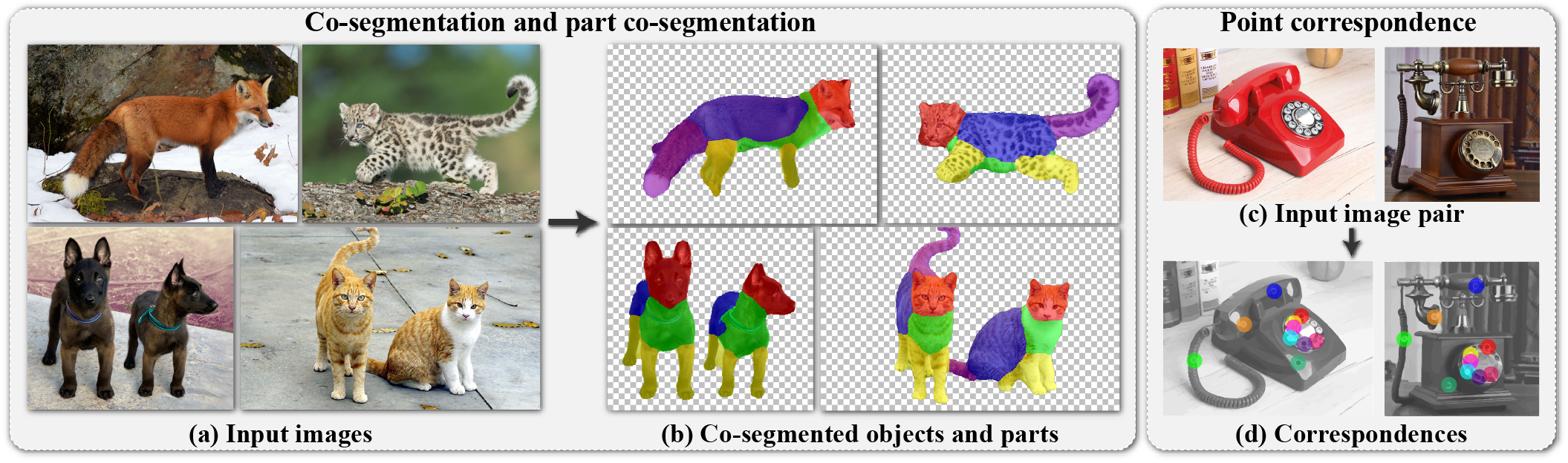
We study the use of deep features extracted from a pretrained Vision Transformer (ViT) as dense visual descriptors. We observe and empirically demonstrate that such features, when extractedfrom a self-supervised ViT model (DINO-ViT), exhibit several striking properties, including: (i) the features encode powerful, well-localized semantic information, at high spatial granularity, such as object parts; (ii) the encoded semantic information is shared across related, yet different object categories, and (iii) positional bias changes gradually throughout the layers. These properties allow us to design simple methods for a variety of applications, including co-segmentation, part co-segmentation and semantic correspondences. To distill the power of ViT features from convoluted design choices, we restrict ourselves to lightweight zero-shot methodologies (e.g., binning and clustering) applied directly to the features. Since our methods require no additional training nor data, they are readily applicable across a variety of domains. We show by extensive qualitative and quantitative evaluation that our simple methodologies achieve competitive results with recent state-of-the-art supervised methods, and outperform previous unsupervised methods by a large margin. Code is available in dino-vit-features.github.io.
PDF Abstract Colab
Colab


 ImageNet
ImageNet
 AFHQ
AFHQ
 SPair-71k
SPair-71k

