Deformable Siamese Attention Networks for Visual Object Tracking
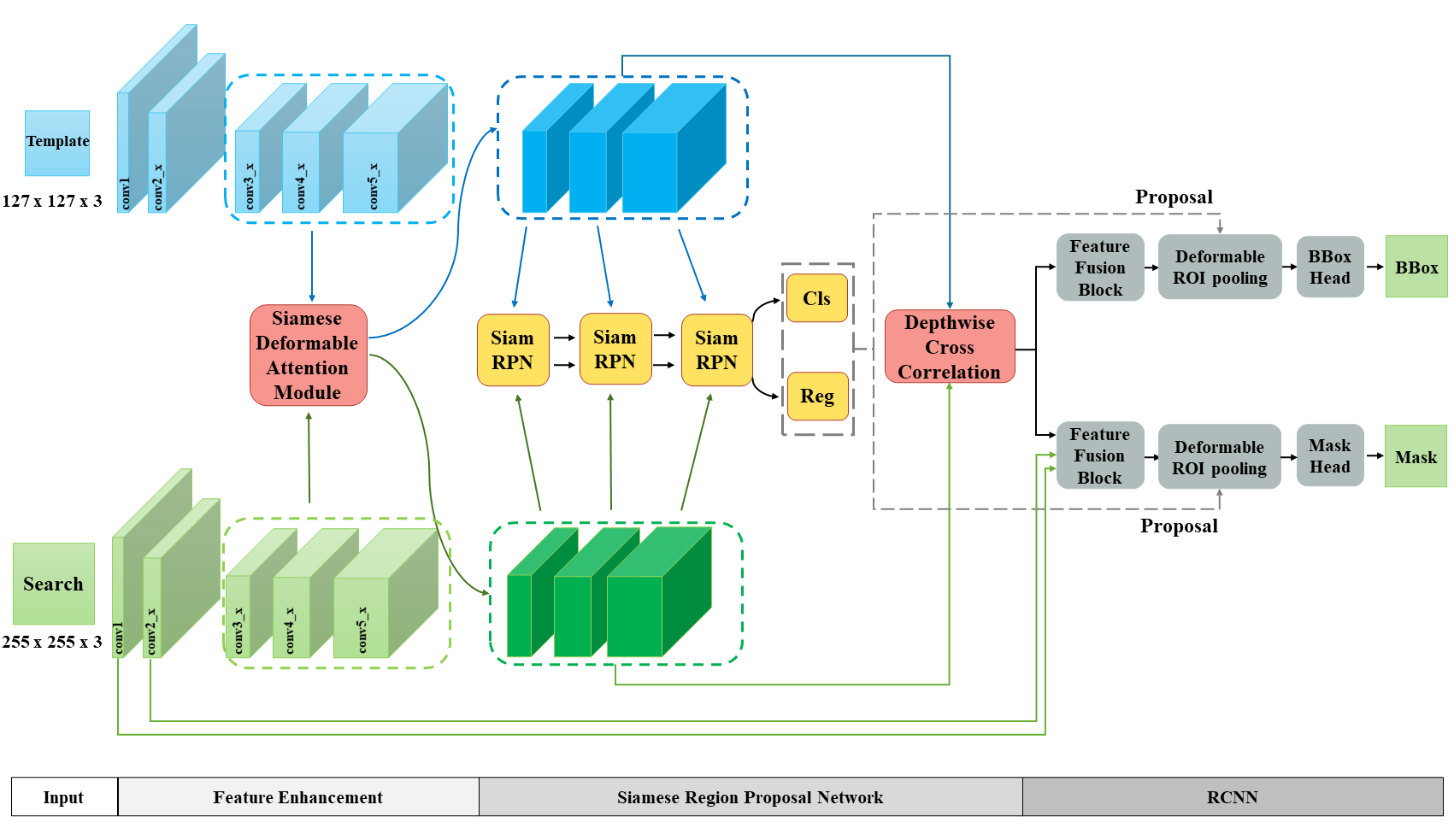
Siamese-based trackers have achieved excellent performance on visual object tracking. However, the target template is not updated online, and the features of the target template and search image are computed independently in a Siamese architecture. In this paper, we propose Deformable Siamese Attention Networks, referred to as SiamAttn, by introducing a new Siamese attention mechanism that computes deformable self-attention and cross-attention. The self attention learns strong context information via spatial attention, and selectively emphasizes interdependent channel-wise features with channel attention. The cross-attention is capable of aggregating rich contextual inter-dependencies between the target template and the search image, providing an implicit manner to adaptively update the target template. In addition, we design a region refinement module that computes depth-wise cross correlations between the attentional features for more accurate tracking. We conduct experiments on six benchmarks, where our method achieves new state of-the-art results, outperforming the strong baseline, SiamRPN++ [24], by 0.464->0.537 and 0.415->0.470 EAO on VOT 2016 and 2018. Our code is available at: https://github.com/msight-tech/research-siamattn.
PDF Abstract CVPR 2020 PDF CVPR 2020 Abstract


 ImageNet
ImageNet
 MS COCO
MS COCO
 OTB
OTB
 LaSOT
LaSOT
 TrackingNet
TrackingNet
 OTB-2015
OTB-2015
 VOT2018
VOT2018
 VOT2016
VOT2016
