Deforming Autoencoders: Unsupervised Disentangling of Shape and Appearance
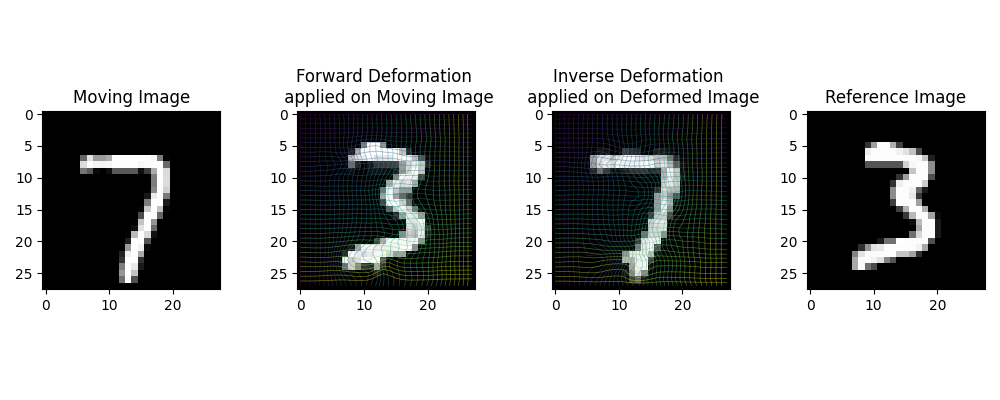
In this work we introduce Deforming Autoencoders, a generative model for images that disentangles shape from appearance in an unsupervised manner. As in the deformable template paradigm, shape is represented as a deformation between a canonical coordinate system (`template') and an observed image, while appearance is modeled in `canonical', template, coordinates, thus discarding variability due to deformations. We introduce novel techniques that allow this approach to be deployed in the setting of autoencoders and show that this method can be used for unsupervised group-wise image alignment. We show experiments with expression morphing in humans, hands, and digits, face manipulation, such as shape and appearance interpolation, as well as unsupervised landmark localization. A more powerful form of unsupervised disentangling becomes possible in template coordinates, allowing us to successfully decompose face images into shading and albedo, and further manipulate face images.
PDF Abstract ECCV 2018 PDF ECCV 2018 Abstract


 CelebA
CelebA
 MAFL
MAFL

