Democratizing Contrastive Language-Image Pre-training: A CLIP Benchmark of Data, Model, and Supervision
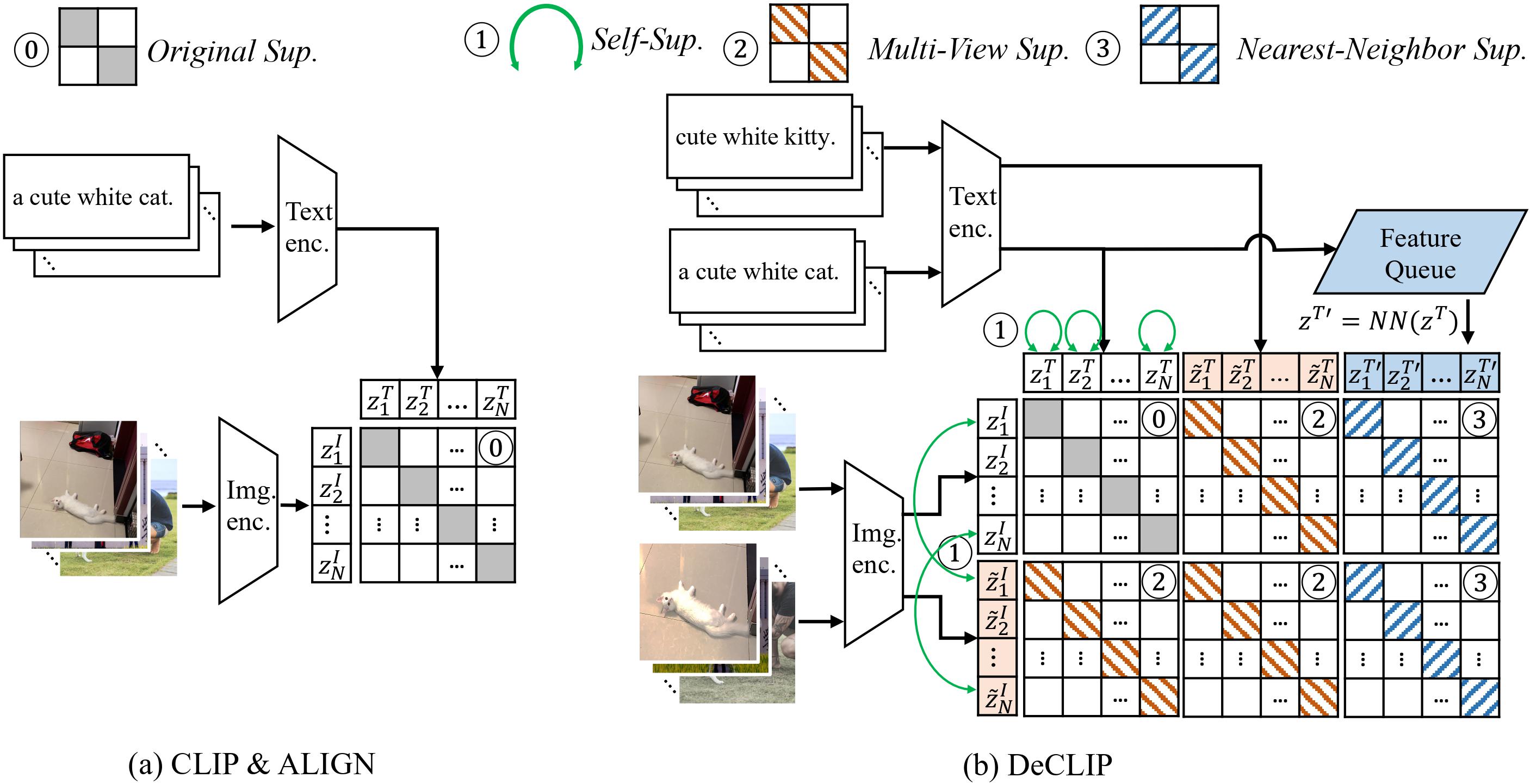
Contrastive Language-Image Pretraining (CLIP) has emerged as a novel paradigm to learn visual models from language supervision. While researchers continue to push the frontier of CLIP, reproducing these works remains challenging. This is because researchers do not choose consistent training recipes and even use different data, hampering the fair comparison between different methods. In this work, we propose CLIP-benchmark, a first attempt to evaluate, analyze, and benchmark CLIP and its variants. We conduct a comprehensive analysis of three key factors: data, supervision, and model architecture. We find considerable intuitive or counter-intuitive insights: (1). Data quality has a significant impact on performance. (2). Certain supervision has different effects for Convolutional Networks (ConvNets) and Vision Transformers (ViT). Applying more proper supervision can effectively improve the performance of CLIP. (3). Curtailing the text encoder reduces the training cost but not much affect the final performance. Moreover, we further combine DeCLIP with FILIP, bringing us the strongest variant DeFILIP. The CLIP-benchmark would be released at: https://github.com/Sense-GVT/DeCLIP for future CLIP research.
PDF Abstract
 ImageNet
ImageNet
