Demystify Transformers & Convolutions in Modern Image Deep Networks
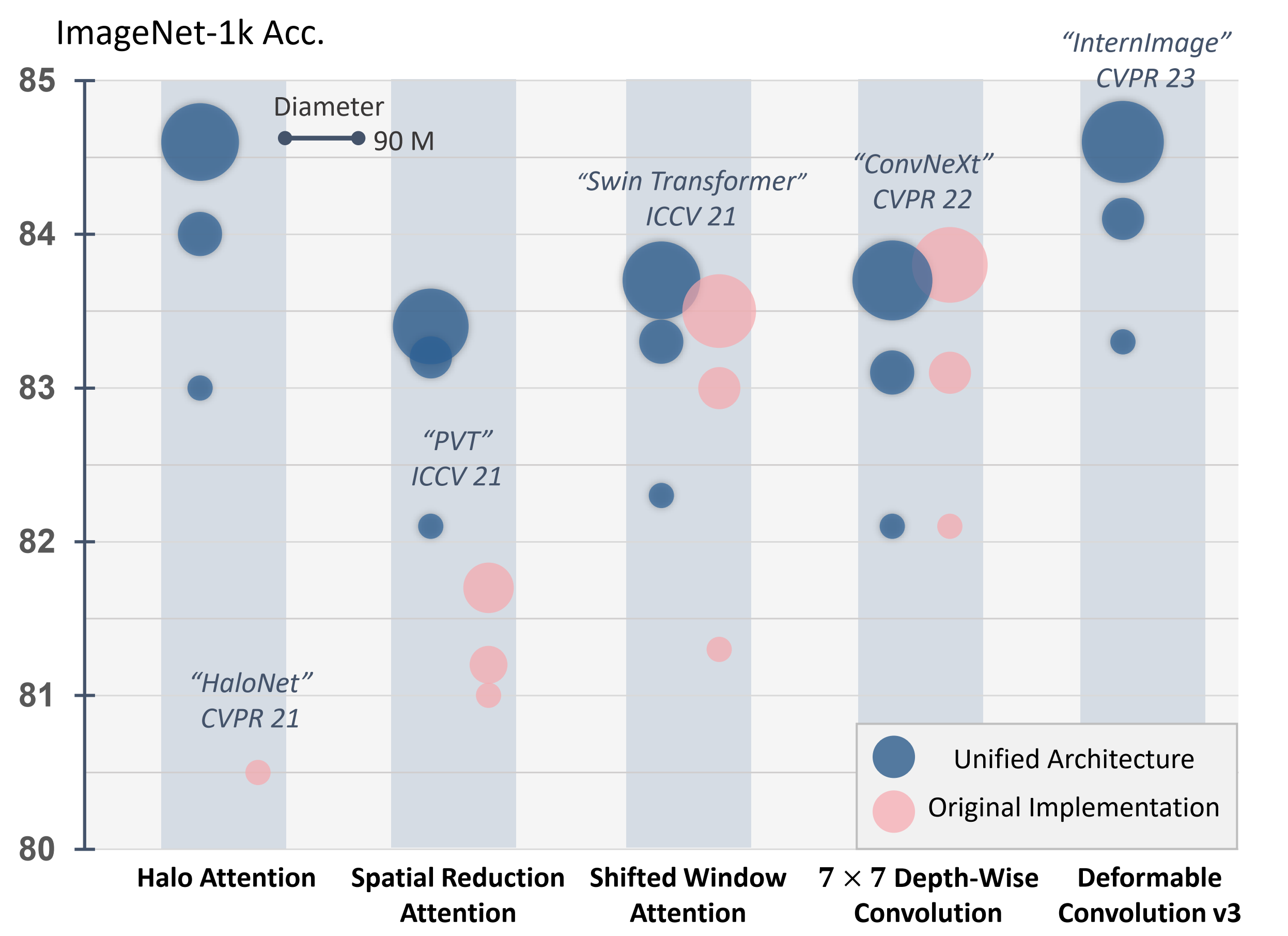
Vision transformers have gained popularity recently, leading to the development of new vision backbones with improved features and consistent performance gains. However, these advancements are not solely attributable to novel feature transformation designs; certain benefits also arise from advanced network-level and block-level architectures. This paper aims to identify the real gains of popular convolution and attention operators through a detailed study. We find that the key difference among these feature transformation modules, such as attention or convolution, lies in their spatial feature aggregation approach, known as the "spatial token mixer" (STM). To facilitate an impartial comparison, we introduce a unified architecture to neutralize the impact of divergent network-level and block-level designs. Subsequently, various STMs are integrated into this unified framework for comprehensive comparative analysis. Our experiments on various tasks and an analysis of inductive bias show a significant performance boost due to advanced network-level and block-level designs, but performance differences persist among different STMs. Our detailed analysis also reveals various findings about different STMs, such as effective receptive fields and invariance tests. All models and codes used in this study are publicly available at \url{https://github.com/OpenGVLab/STM-Evaluation}.
PDF Abstract

 ImageNet
ImageNet
 MS COCO
MS COCO
