Dep-$L_0$: Improving $L_0$-based Network Sparsification via Dependency Modeling
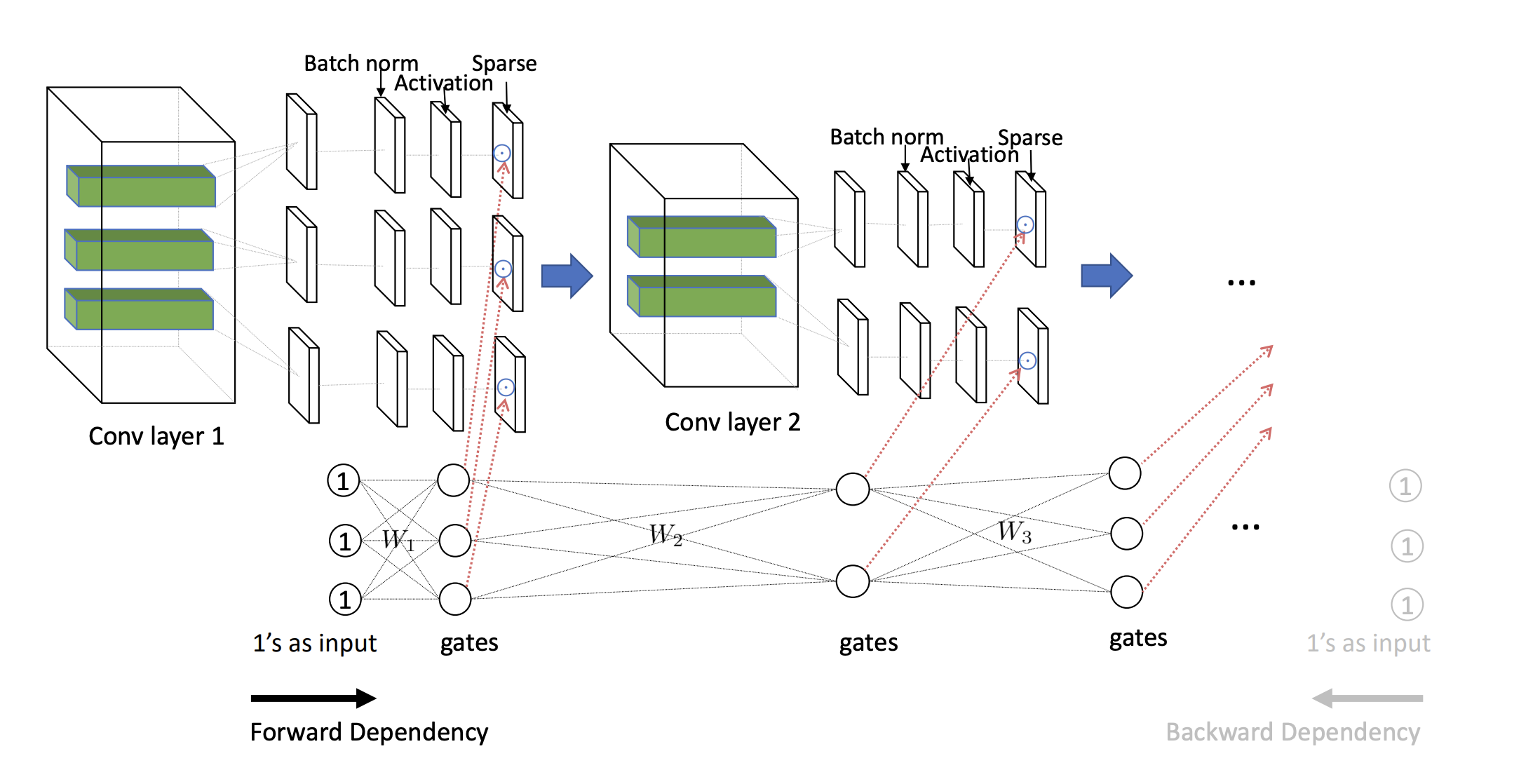
Training deep neural networks with an $L_0$ regularization is one of the prominent approaches for network pruning or sparsification. The method prunes the network during training by encouraging weights to become exactly zero. However, recent work of Gale et al. reveals that although this method yields high compression rates on smaller datasets, it performs inconsistently on large-scale learning tasks, such as ResNet50 on ImageNet. We analyze this phenomenon through the lens of variational inference and find that it is likely due to the independent modeling of binary gates, the mean-field approximation, which is known in Bayesian statistics for its poor performance due to the crude approximation. To mitigate this deficiency, we propose a dependency modeling of binary gates, which can be modeled effectively as a multi-layer perceptron (MLP). We term our algorithm Dep-$L_0$ as it prunes networks via a dependency-enabled $L_0$ regularization. Extensive experiments on CIFAR10, CIFAR100 and ImageNet with VGG16, ResNet50, ResNet56 show that our Dep-$L_0$ outperforms the original $L_0$-HC algorithm of Louizos et al. by a significant margin, especially on ImageNet. Compared with the state-of-the-arts network sparsification algorithms, our dependency modeling makes the $L_0$-based sparsification once again very competitive on large-scale learning tasks. Our source code is available at https://github.com/leo-yangli/dep-l0.
PDF Abstract

 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
