Depth-conditioned Dynamic Message Propagation for Monocular 3D Object Detection
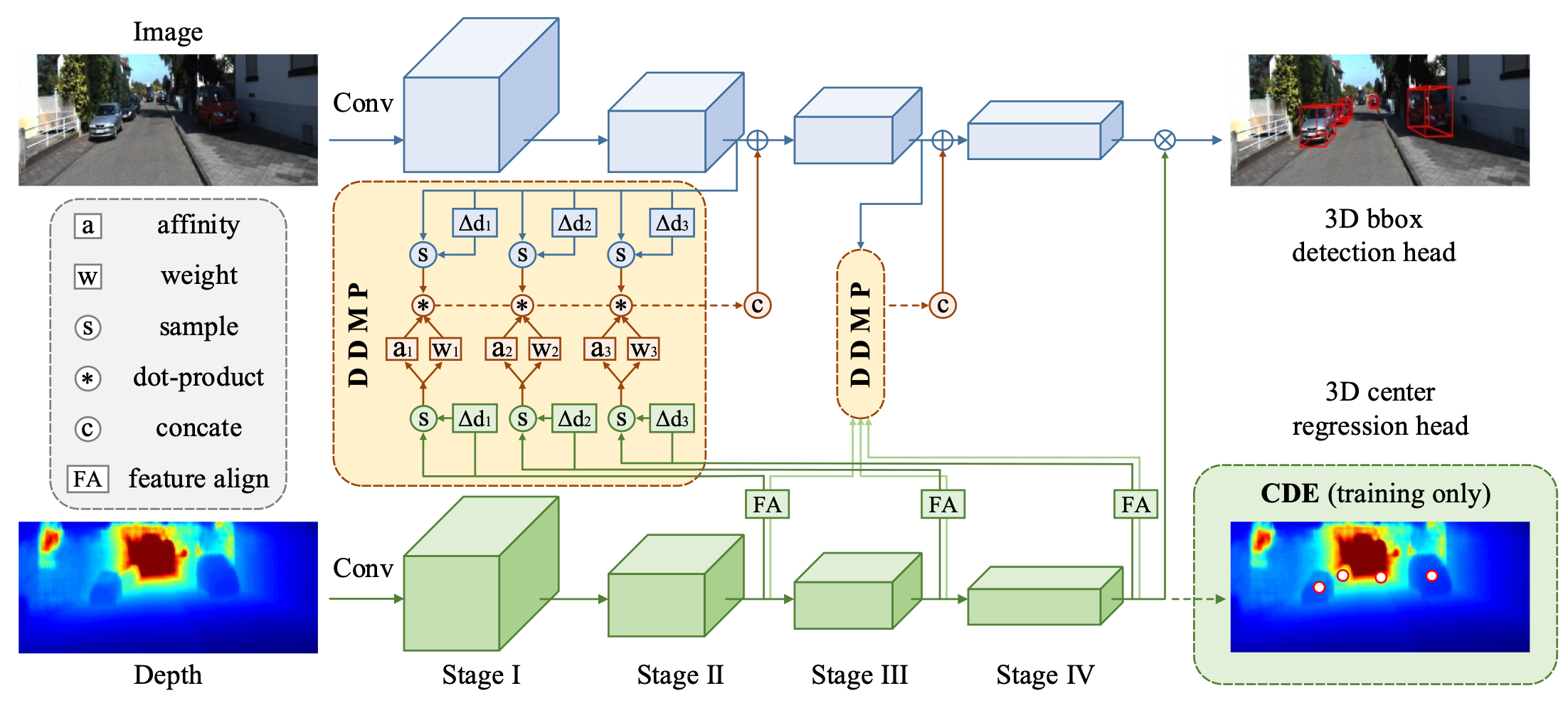
The objective of this paper is to learn context- and depth-aware feature representation to solve the problem of monocular 3D object detection. We make following contributions: (i) rather than appealing to the complicated pseudo-LiDAR based approach, we propose a depth-conditioned dynamic message propagation (DDMP) network to effectively integrate the multi-scale depth information with the image context;(ii) this is achieved by first adaptively sampling context-aware nodes in the image context and then dynamically predicting hybrid depth-dependent filter weights and affinity matrices for propagating information; (iii) by augmenting a center-aware depth encoding (CDE) task, our method successfully alleviates the inaccurate depth prior; (iv) we thoroughly demonstrate the effectiveness of our proposed approach and show state-of-the-art results among the monocular-based approaches on the KITTI benchmark dataset. Particularly, we rank $1^{st}$ in the highly competitive KITTI monocular 3D object detection track on the submission day (November 16th, 2020). Code and models are released at \url{https://github.com/fudan-zvg/DDMP}
PDF Abstract CVPR 2021 PDF CVPR 2021 Abstract



 KITTI
KITTI

