Detail Preserved Point Cloud Completion via Separated Feature Aggregation
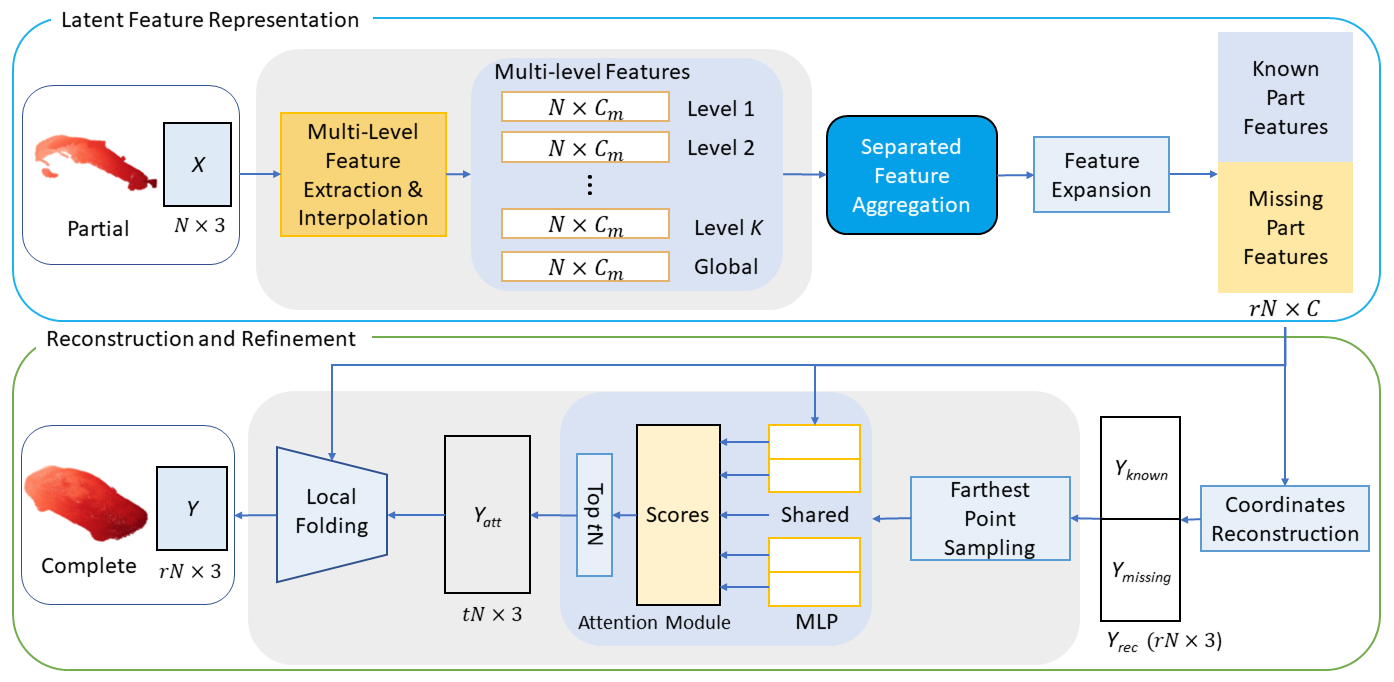
Point cloud shape completion is a challenging problem in 3D vision and robotics. Existing learning-based frameworks leverage encoder-decoder architectures to recover the complete shape from a highly encoded global feature vector. Though the global feature can approximately represent the overall shape of 3D objects, it would lead to the loss of shape details during the completion process. In this work, instead of using a global feature to recover the whole complete surface, we explore the functionality of multi-level features and aggregate different features to represent the known part and the missing part separately. We propose two different feature aggregation strategies, named global \& local feature aggregation(GLFA) and residual feature aggregation(RFA), to express the two kinds of features and reconstruct coordinates from their combination. In addition, we also design a refinement component to prevent the generated point cloud from non-uniform distribution and outliers. Extensive experiments have been conducted on the ShapeNet dataset. Qualitative and quantitative evaluations demonstrate that our proposed network outperforms current state-of-the art methods especially on detail preservation.
PDF Abstract ECCV 2020 PDF ECCV 2020 Abstract

