Detecting Adversarial Examples via Neural Fingerprinting
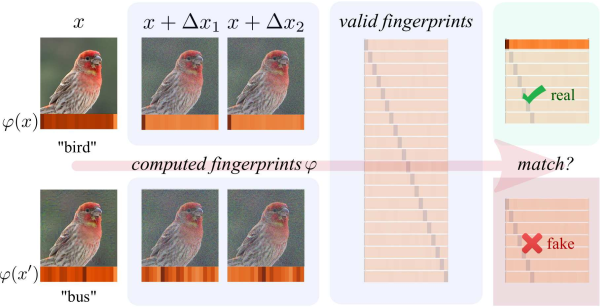
Deep neural networks are vulnerable to adversarial examples, which dramatically alter model output using small input changes. We propose Neural Fingerprinting, a simple, yet effective method to detect adversarial examples by verifying whether model behavior is consistent with a set of secret fingerprints, inspired by the use of biometric and cryptographic signatures. The benefits of our method are that 1) it is fast, 2) it is prohibitively expensive for an attacker to reverse-engineer which fingerprints were used, and 3) it does not assume knowledge of the adversary. In this work, we pose a formal framework to analyze fingerprints under various threat models, and characterize Neural Fingerprinting for linear models. For complex neural networks, we empirically demonstrate that Neural Fingerprinting significantly improves on state-of-the-art detection mechanisms by detecting the strongest known adversarial attacks with 98-100% AUC-ROC scores on the MNIST, CIFAR-10 and MiniImagenet (20 classes) datasets. In particular, the detection accuracy of Neural Fingerprinting generalizes well to unseen test-data under various black- and whitebox threat models, and is robust over a wide range of hyperparameters and choices of fingerprints.
PDF Abstract
