Detecting Errors and Estimating Accuracy on Unlabeled Data with Self-training Ensembles
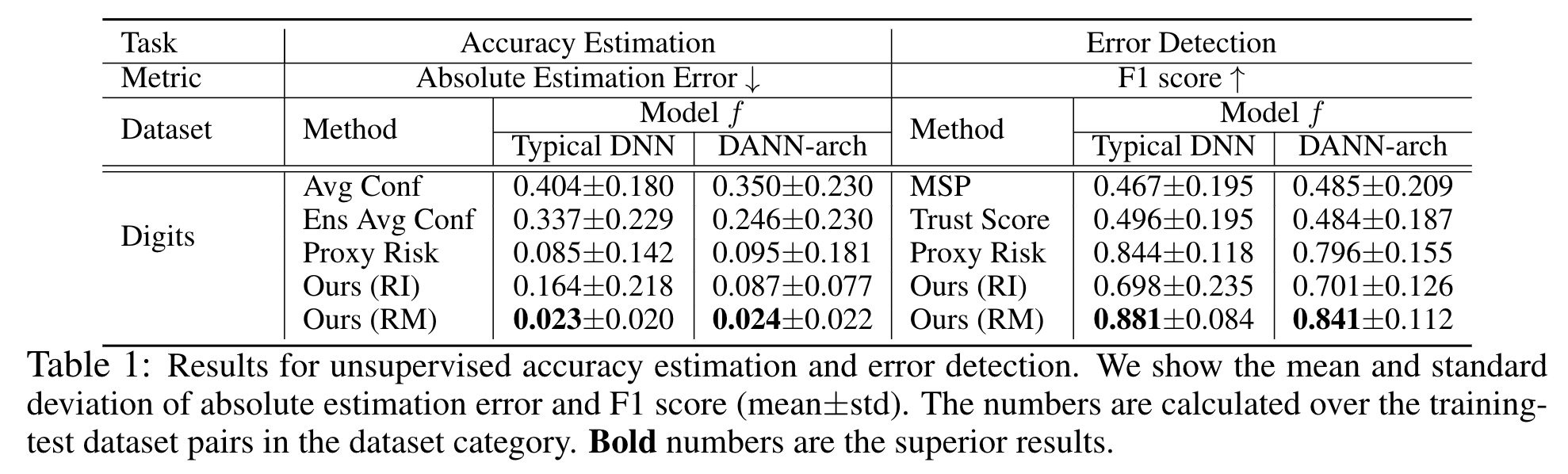
When a deep learning model is deployed in the wild, it can encounter test data drawn from distributions different from the training data distribution and suffer drop in performance. For safe deployment, it is essential to estimate the accuracy of the pre-trained model on the test data. However, the labels for the test inputs are usually not immediately available in practice, and obtaining them can be expensive. This observation leads to two challenging tasks: (1) unsupervised accuracy estimation, which aims to estimate the accuracy of a pre-trained classifier on a set of unlabeled test inputs; (2) error detection, which aims to identify mis-classified test inputs. In this paper, we propose a principled and practically effective framework that simultaneously addresses the two tasks. The proposed framework iteratively learns an ensemble of models to identify mis-classified data points and performs self-training to improve the ensemble with the identified points. Theoretical analysis demonstrates that our framework enjoys provable guarantees for both accuracy estimation and error detection under mild conditions readily satisfied by practical deep learning models. Along with the framework, we proposed and experimented with two instantiations and achieved state-of-the-art results on 59 tasks. For example, on iWildCam, one instantiation reduces the estimation error for unsupervised accuracy estimation by at least 70% and improves the F1 score for error detection by at least 4.7% compared to existing methods.
PDF Abstract NeurIPS 2021 PDF NeurIPS 2021 Abstract
 CIFAR-10
CIFAR-10
 MNIST
MNIST
 SVHN
SVHN
 Office-31
Office-31
 USPS
USPS
 MNIST-M
MNIST-M
