DiffBEV: Conditional Diffusion Model for Bird's Eye View Perception
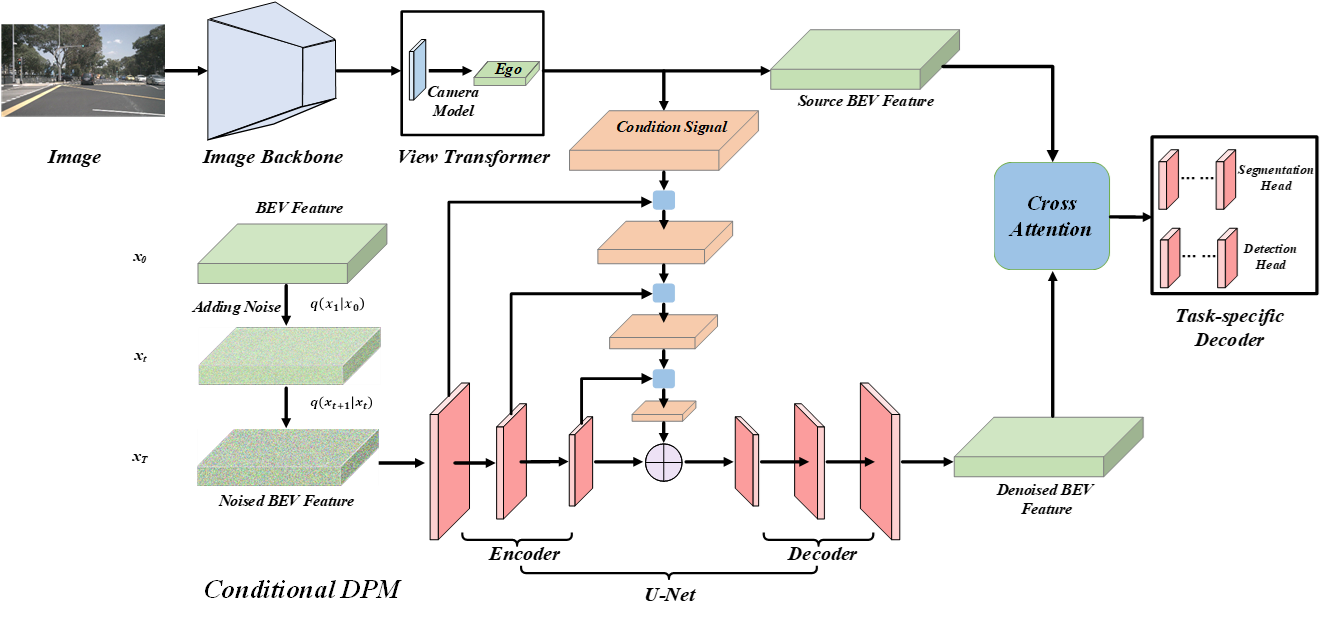
BEV perception is of great importance in the field of autonomous driving, serving as the cornerstone of planning, controlling, and motion prediction. The quality of the BEV feature highly affects the performance of BEV perception. However, taking the noises in camera parameters and LiDAR scans into consideration, we usually obtain BEV representation with harmful noises. Diffusion models naturally have the ability to denoise noisy samples to the ideal data, which motivates us to utilize the diffusion model to get a better BEV representation. In this work, we propose an end-to-end framework, named DiffBEV, to exploit the potential of diffusion model to generate a more comprehensive BEV representation. To the best of our knowledge, we are the first to apply diffusion model to BEV perception. In practice, we design three types of conditions to guide the training of the diffusion model which denoises the coarse samples and refines the semantic feature in a progressive way. What's more, a cross-attention module is leveraged to fuse the context of BEV feature and the semantic content of conditional diffusion model. DiffBEV achieves a 25.9% mIoU on the nuScenes dataset, which is 6.2% higher than the best-performing existing approach. Quantitative and qualitative results on multiple benchmarks demonstrate the effectiveness of DiffBEV in BEV semantic segmentation and 3D object detection tasks. The code will be available soon.
PDF Abstract





 KITTI
KITTI
 nuScenes
nuScenes
