DiffIR: Efficient Diffusion Model for Image Restoration
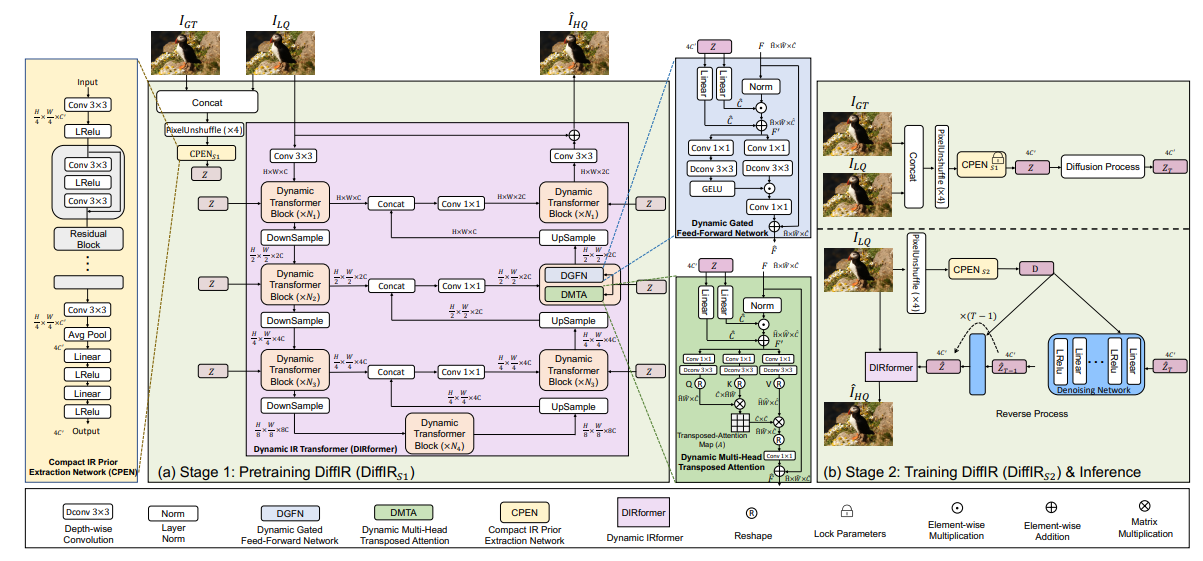
Diffusion model (DM) has achieved SOTA performance by modeling the image synthesis process into a sequential application of a denoising network. However, different from image synthesis, image restoration (IR) has a strong constraint to generate results in accordance with ground-truth. Thus, for IR, traditional DMs running massive iterations on a large model to estimate whole images or feature maps is inefficient. To address this issue, we propose an efficient DM for IR (DiffIR), which consists of a compact IR prior extraction network (CPEN), dynamic IR transformer (DIRformer), and denoising network. Specifically, DiffIR has two training stages: pretraining and training DM. In pretraining, we input ground-truth images into CPEN$_{S1}$ to capture a compact IR prior representation (IPR) to guide DIRformer. In the second stage, we train the DM to directly estimate the same IRP as pretrained CPEN$_{S1}$ only using LQ images. We observe that since the IPR is only a compact vector, DiffIR can use fewer iterations than traditional DM to obtain accurate estimations and generate more stable and realistic results. Since the iterations are few, our DiffIR can adopt a joint optimization of CPEN$_{S2}$, DIRformer, and denoising network, which can further reduce the estimation error influence. We conduct extensive experiments on several IR tasks and achieve SOTA performance while consuming less computational costs. Code is available at \url{https://github.com/Zj-BinXia/DiffIR}.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract



 Places
Places
 CelebA-HQ
CelebA-HQ
 DIV2K
DIV2K
 Urban100
Urban100
 Set14
Set14
 GoPro
GoPro
 General-100
General-100
