Dissected 3D CNNs: Temporal Skip Connections for Efficient Online Video Processing
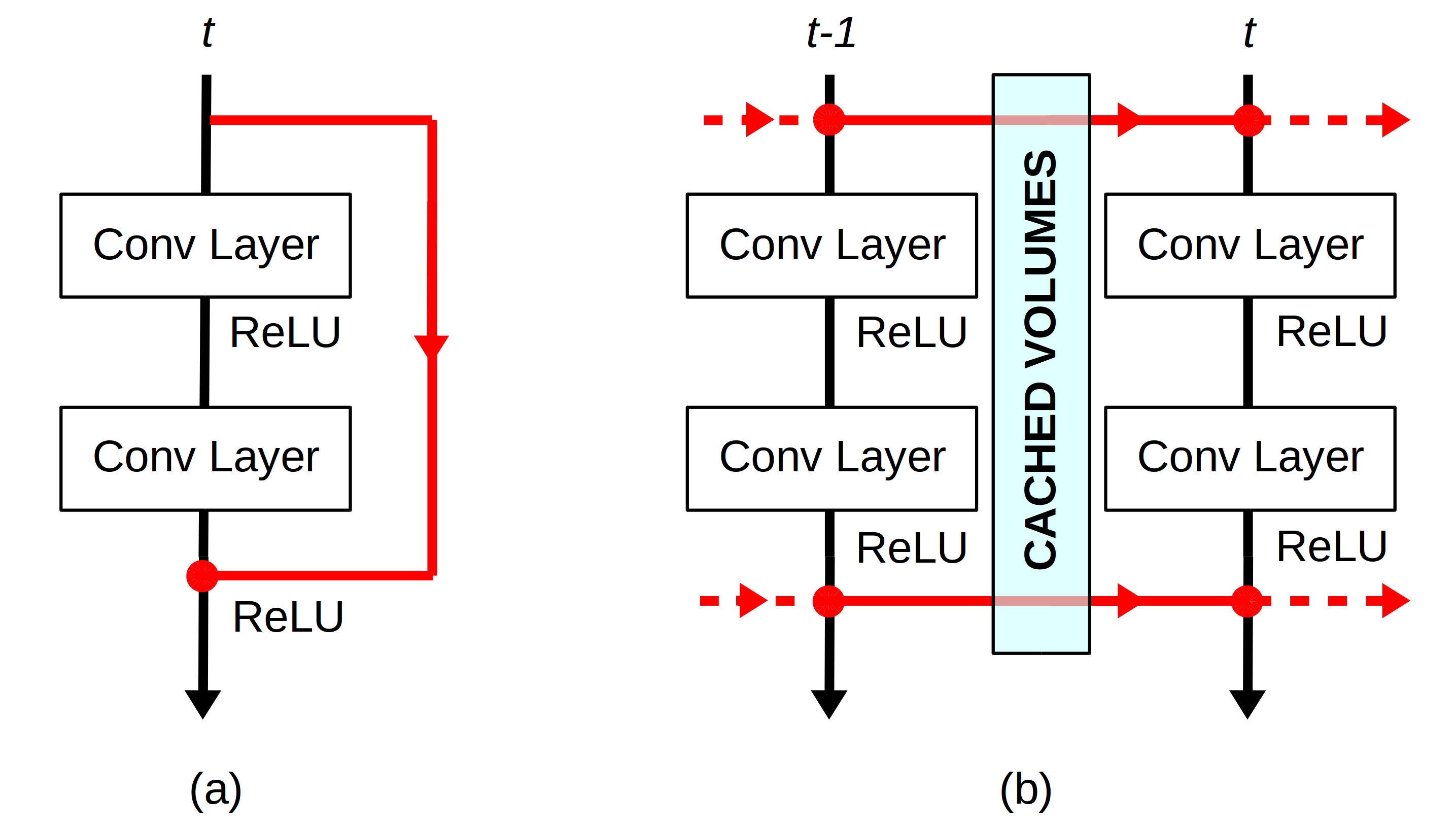
Convolutional Neural Networks with 3D kernels (3D-CNNs) currently achieve state-of-the-art results in video recognition tasks due to their supremacy in extracting spatiotemporal features within video frames. There have been many successful 3D-CNN architectures surpassing the state-of-the-art results successively. However, nearly all of them are designed to operate offline creating several serious handicaps during online operation. Firstly, conventional 3D-CNNs are not dynamic since their output features represent the complete input clip instead of the most recent frame in the clip. Secondly, they are not temporal resolution-preserving due to their inherent temporal downsampling. Lastly, 3D-CNNs are constrained to be used with fixed temporal input size limiting their flexibility. In order to address these drawbacks, we propose dissected 3D-CNNs, where the intermediate volumes of the network are dissected and propagated over depth (time) dimension for future calculations, substantially reducing the number of computations at online operation. For action classification, the dissected version of ResNet models performs 77-90% fewer computations at online operation while achieving ~5% better classification accuracy on the Kinetics-600 dataset than conventional 3D-ResNet models. Moreover, the advantages of dissected 3D-CNNs are demonstrated by deploying our approach onto several vision tasks, which consistently improved the performance.
PDF Abstract


 ActivityNet
ActivityNet
 VoxCeleb2
VoxCeleb2
 MARS
MARS
