Distributed Non-Convex Optimization with Sublinear Speedup under Intermittent Client Availability
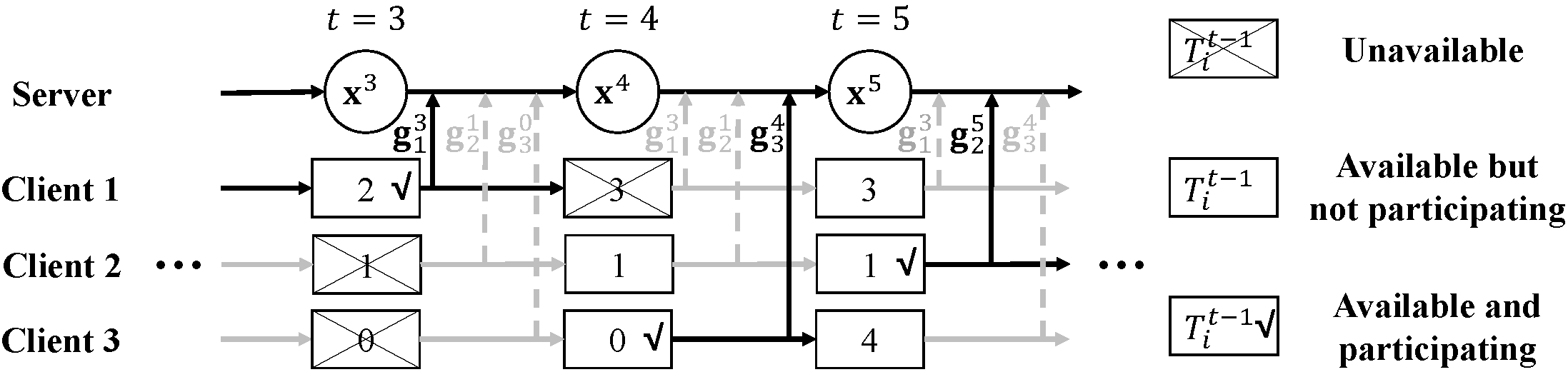
Federated learning is a new distributed machine learning framework, where a bunch of heterogeneous clients collaboratively train a model without sharing training data. In this work, we consider a practical and ubiquitous issue when deploying federated learning in mobile environments: intermittent client availability, where the set of eligible clients may change during the training process. Such intermittent client availability would seriously deteriorate the performance of the classical Federated Averaging algorithm (FedAvg for short). Thus, we propose a simple distributed non-convex optimization algorithm, called Federated Latest Averaging (FedLaAvg for short), which leverages the latest gradients of all clients, even when the clients are not available, to jointly update the global model in each iteration. Our theoretical analysis shows that FedLaAvg attains the convergence rate of $O(E^{1/2}/(N^{1/4} T^{1/2}))$, achieving a sublinear speedup with respect to the total number of clients. We implement FedLaAvg along with several baselines and evaluate them over the benchmarking MNIST and Sentiment140 datasets. The evaluation results demonstrate that FedLaAvg achieves more stable training than FedAvg in both convex and non-convex settings and indeed reaches a sublinear speedup.
PDF Abstract

 CIFAR-10
CIFAR-10
