Distributional Policy Optimization: An Alternative Approach for Continuous Control
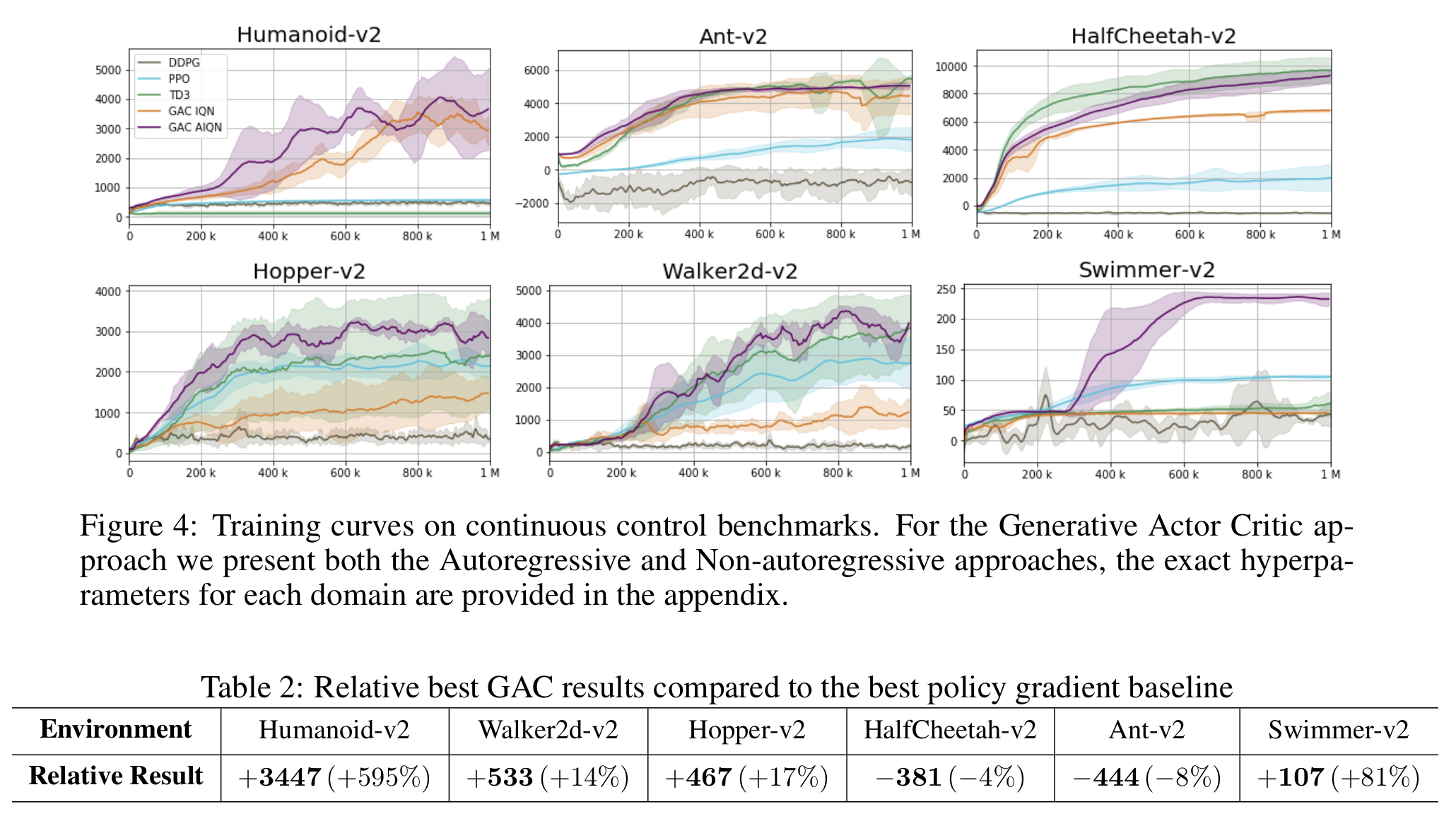
We identify a fundamental problem in policy gradient-based methods in continuous control. As policy gradient methods require the agent's underlying probability distribution, they limit policy representation to parametric distribution classes. We show that optimizing over such sets results in local movement in the action space and thus convergence to sub-optimal solutions. We suggest a novel distributional framework, able to represent arbitrary distribution functions over the continuous action space. Using this framework, we construct a generative scheme, trained using an off-policy actor-critic paradigm, which we call the Generative Actor Critic (GAC). Compared to policy gradient methods, GAC does not require knowledge of the underlying probability distribution, thereby overcoming these limitations. Empirical evaluation shows that our approach is comparable and often surpasses current state-of-the-art baselines in continuous domains.
PDF Abstract NeurIPS 2019 PDF NeurIPS 2019 Abstract


 MuJoCo
MuJoCo
