DMRM: A Dual-channel Multi-hop Reasoning Model for Visual Dialog
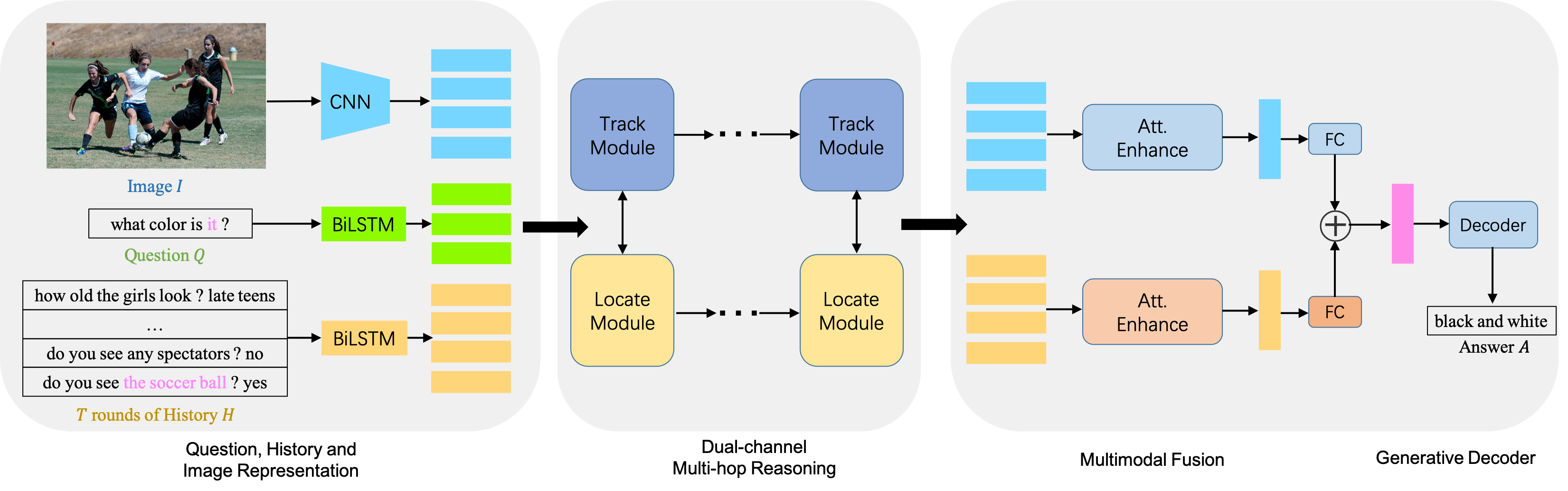
Visual Dialog is a vision-language task that requires an AI agent to engage in a conversation with humans grounded in an image. It remains a challenging task since it requires the agent to fully understand a given question before making an appropriate response not only from the textual dialog history, but also from the visually-grounded information. While previous models typically leverage single-hop reasoning or single-channel reasoning to deal with this complex multimodal reasoning task, which is intuitively insufficient. In this paper, we thus propose a novel and more powerful Dual-channel Multi-hop Reasoning Model for Visual Dialog, named DMRM. DMRM synchronously captures information from the dialog history and the image to enrich the semantic representation of the question by exploiting dual-channel reasoning. Specifically, DMRM maintains a dual channel to obtain the question- and history-aware image features and the question- and image-aware dialog history features by a mulit-hop reasoning process in each channel. Additionally, we also design an effective multimodal attention to further enhance the decoder to generate more accurate responses. Experimental results on the VisDial v0.9 and v1.0 datasets demonstrate that the proposed model is effective and outperforms compared models by a significant margin.
PDF Abstract


 VisDial
VisDial
