Doc-GCN: Heterogeneous Graph Convolutional Networks for Document Layout Analysis
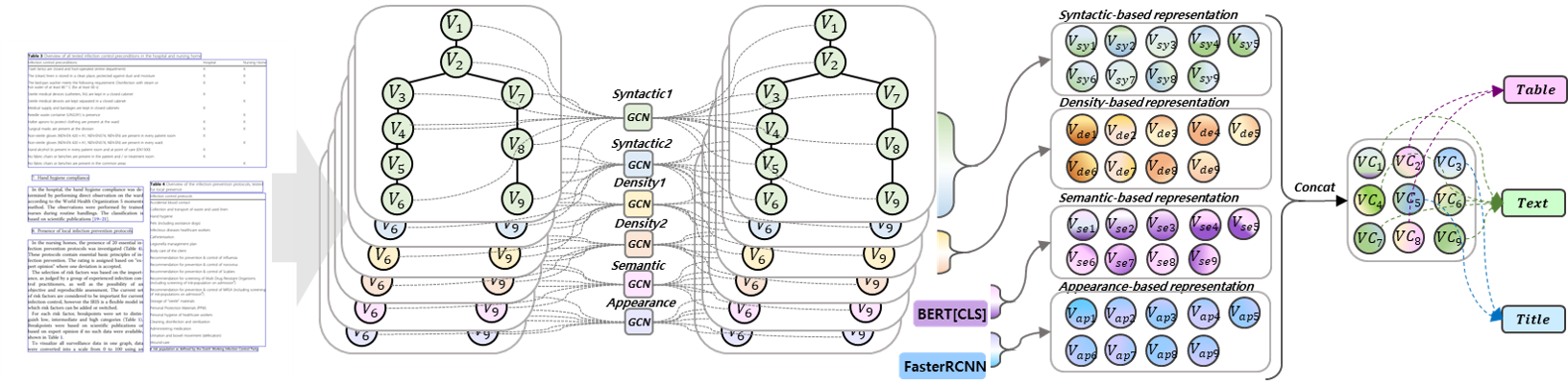
Recognizing the layout of unstructured digital documents is crucial when parsing the documents into the structured, machine-readable format for downstream applications. Recent studies in Document Layout Analysis usually rely on computer vision models to understand documents while ignoring other information, such as context information or relation of document components, which are vital to capture. Our Doc-GCN presents an effective way to harmonize and integrate heterogeneous aspects for Document Layout Analysis. We first construct graphs to explicitly describe four main aspects, including syntactic, semantic, density, and appearance/visual information. Then, we apply graph convolutional networks for representing each aspect of information and use pooling to integrate them. Finally, we aggregate each aspect and feed them into 2-layer MLPs for document layout component classification. Our Doc-GCN achieves new state-of-the-art results in three widely used DLA datasets.
PDF Abstract COLING 2022 PDF COLING 2022 Abstract Colab
Colab



 FUNSD
FUNSD
