Document Intelligence Metrics for Visually Rich Document Evaluation
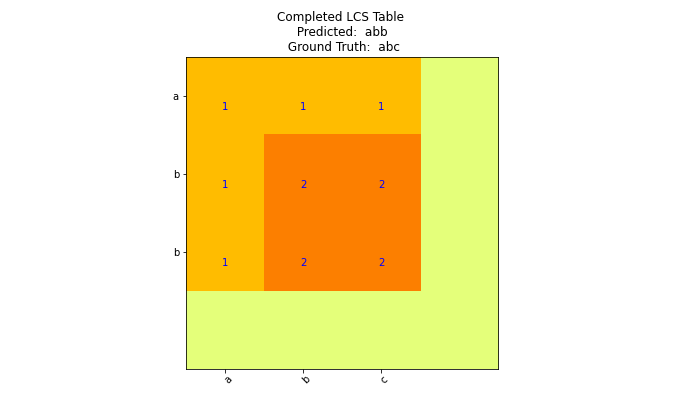
The processing of Visually-Rich Documents (VRDs) is highly important in information extraction tasks associated with Document Intelligence. We introduce DI-Metrics, a Python library devoted to VRD model evaluation comprising text-based, geometric-based and hierarchical metrics for information extraction tasks. We apply DI-Metrics to evaluate information extraction performance using publicly available CORD dataset, comparing performance of three SOTA models and one industry model. The open-source library is available on GitHub.
PDF AbstractCode
Tasks

Datasets
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
