An Effective Domain Adaptive Post-Training Method for BERT in Response Selection
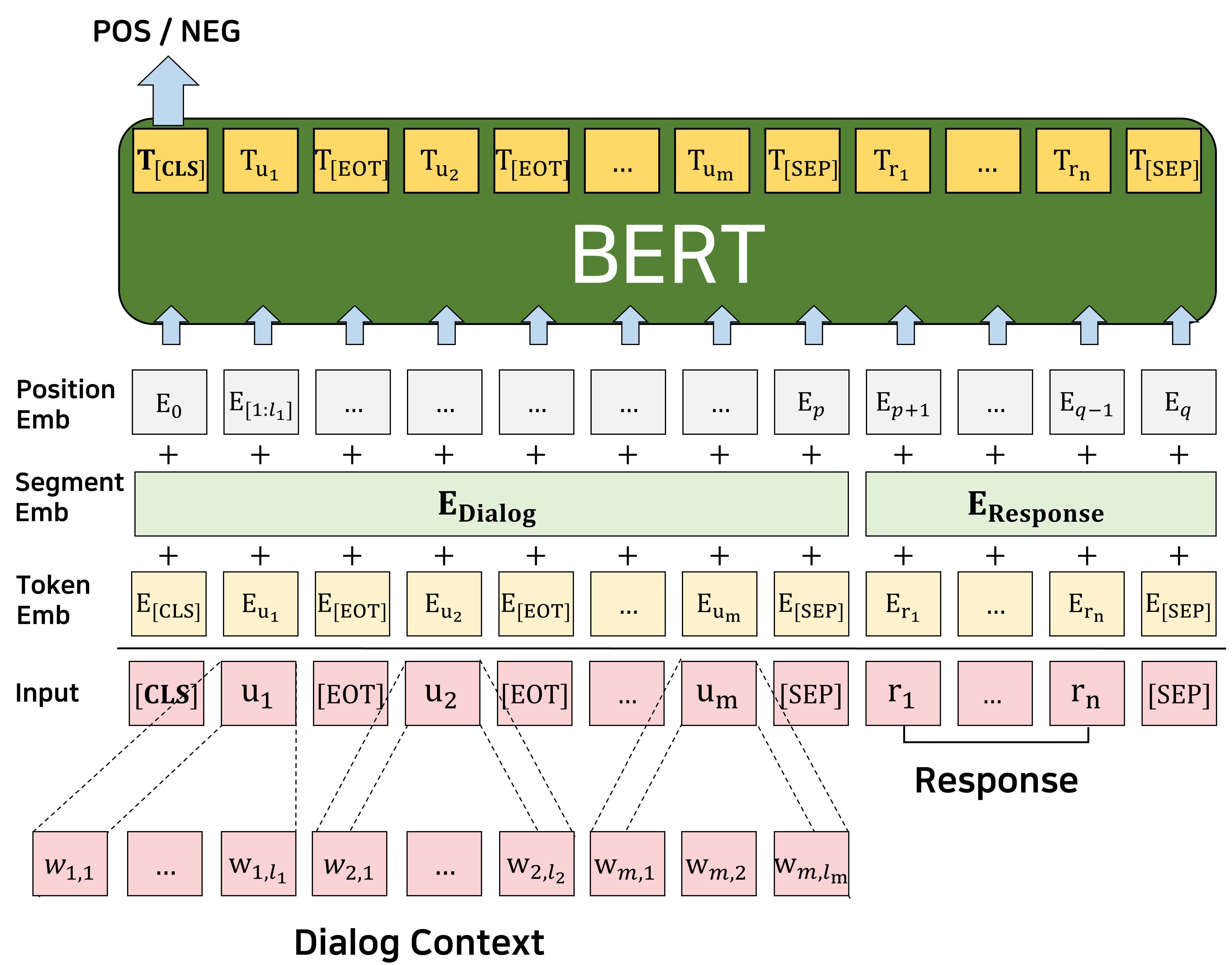
We focus on multi-turn response selection in a retrieval-based dialog system. In this paper, we utilize the powerful pre-trained language model Bi-directional Encoder Representations from Transformer (BERT) for a multi-turn dialog system and propose a highly effective post-training method on domain-specific corpus. Although BERT is easily adopted to various NLP tasks and outperforms previous baselines of each task, it still has limitations if a task corpus is too focused on a certain domain. Post-training on domain-specific corpus (e.g., Ubuntu Corpus) helps the model to train contextualized representations and words that do not appear in general corpus (e.g., English Wikipedia). Experimental results show that our approach achieves new state-of-the-art on two response selection benchmarks (i.e., Ubuntu Corpus V1, Advising Corpus) performance improvement by 5.9% and 6% on R@1.
PDF Abstract


 UDC
UDC
 Advising Corpus
Advising Corpus

