Domain Adaptive Video Segmentation via Temporal Pseudo Supervision
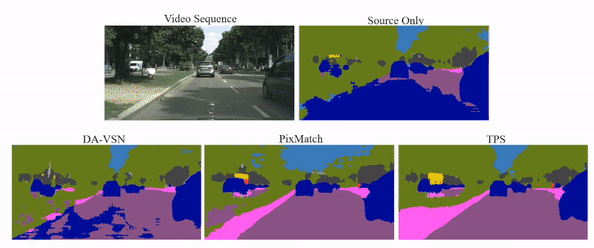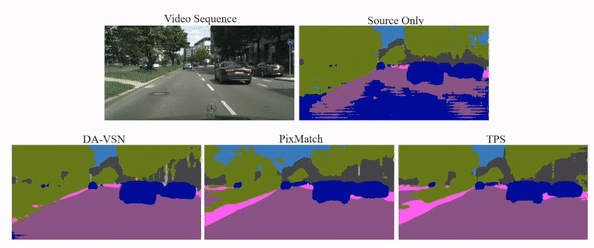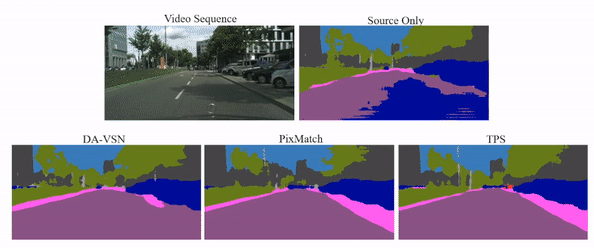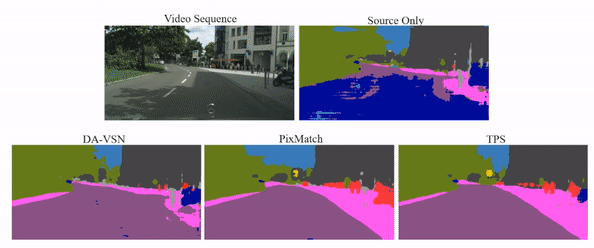
Video semantic segmentation has achieved great progress under the supervision of large amounts of labelled training data. However, domain adaptive video segmentation, which can mitigate data labelling constraints by adapting from a labelled source domain toward an unlabelled target domain, is largely neglected. We design temporal pseudo supervision (TPS), a simple and effective method that explores the idea of consistency training for learning effective representations from unlabelled target videos. Unlike traditional consistency training that builds consistency in spatial space, we explore consistency training in spatiotemporal space by enforcing model consistency across augmented video frames which helps learn from more diverse target data. Specifically, we design cross-frame pseudo labelling to provide pseudo supervision from previous video frames while learning from the augmented current video frames. The cross-frame pseudo labelling encourages the network to produce high-certainty predictions, which facilitates consistency training with cross-frame augmentation effectively. Extensive experiments over multiple public datasets show that TPS is simpler to implement, much more stable to train, and achieves superior video segmentation accuracy as compared with the state-of-the-art.
PDF Abstract


 Cityscapes
Cityscapes
