Dual Adversarial Adaptation for Cross-Device Real-World Image Super-Resolution
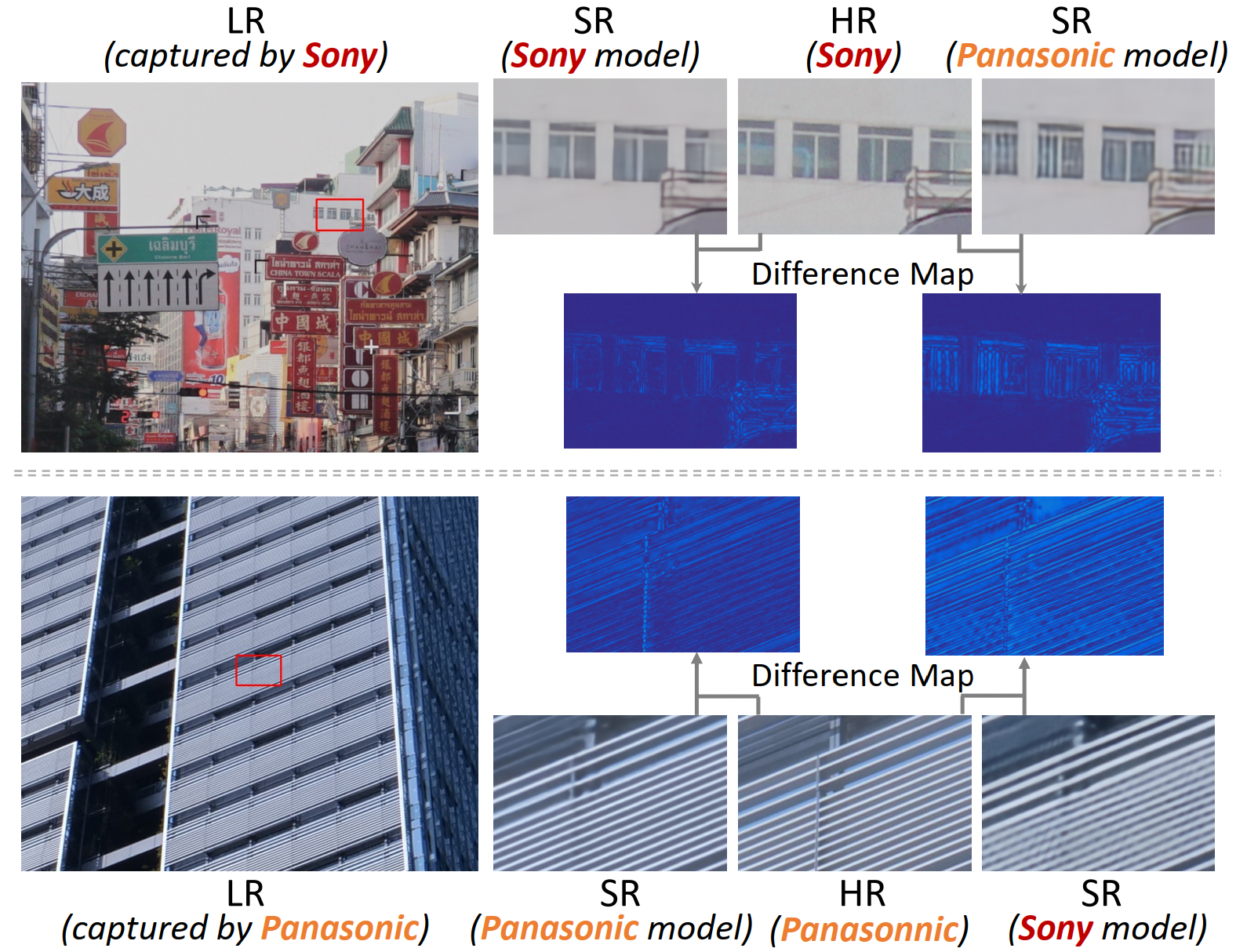
Due to the sophisticated imaging process, an identical scene captured by different cameras could exhibit distinct imaging patterns, introducing distinct proficiency among the super-resolution (SR) models trained on images from different devices. In this paper, we investigate a novel and practical task coded cross-device SR, which strives to adapt a real-world SR model trained on the paired images captured by one camera to low-resolution (LR) images captured by arbitrary target devices. The proposed task is highly challenging due to the absence of paired data from various imaging devices. To address this issue, we propose an unsupervised domain adaptation mechanism for real-world SR, named Dual ADversarial Adaptation (DADA), which only requires LR images in the target domain with available real paired data from a source camera. DADA employs the Domain-Invariant Attention (DIA) module to establish the basis of target model training even without HR supervision. Furthermore, the dual framework of DADA facilitates an Inter-domain Adversarial Adaptation (InterAA) in one branch for two LR input images from two domains, and an Intra-domain Adversarial Adaptation (IntraAA) in two branches for an LR input image. InterAA and IntraAA together improve the model transferability from the source domain to the target. We empirically conduct experiments under six Real to Real adaptation settings among three different cameras, and achieve superior performance compared with existing state-of-the-art approaches. We also evaluate the proposed DADA to address the adaptation to the video camera, which presents a promising research topic to promote the wide applications of real-world super-resolution. Our source code is publicly available at https://github.com/lonelyhope/DADA.git.
PDF Abstract CVPR 2022 PDF CVPR 2022 Abstract




