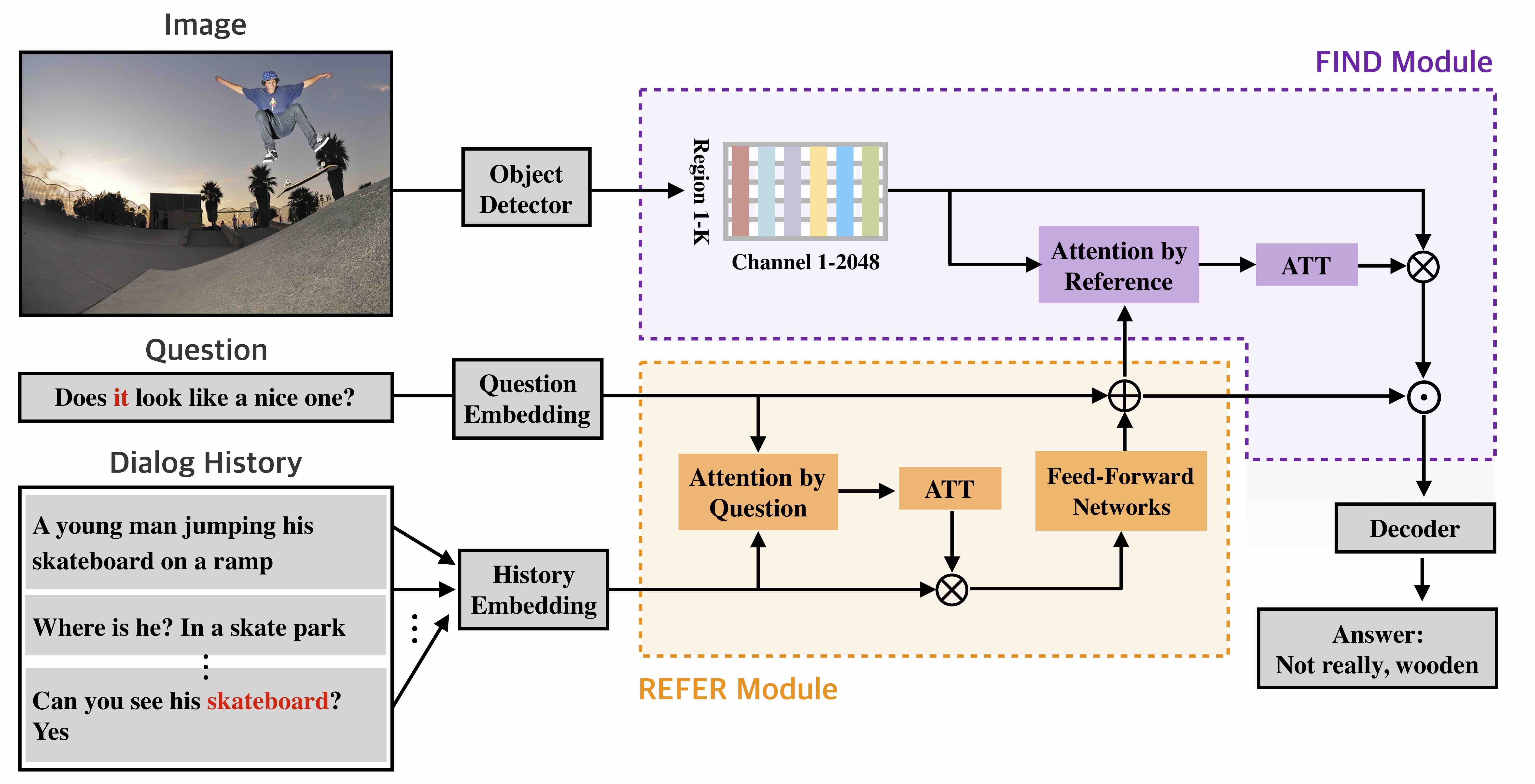
Dual Attention Networks for Visual Reference Resolution in Visual Dialog
Visual dialog (VisDial) is a task which requires an AI agent to answer a series of questions grounded in an image. Unlike in visual question answering (VQA), the series of questions should be able to capture a temporal context from a dialog history and exploit visually-grounded information. A problem called visual reference resolution involves these challenges, requiring the agent to resolve ambiguous references in a given question and find the references in a given image. In this paper, we propose Dual Attention Networks (DAN) for visual reference resolution. DAN consists of two kinds of attention networks, REFER and FIND. Specifically, REFER module learns latent relationships between a given question and a dialog history by employing a self-attention mechanism. FIND module takes image features and reference-aware representations (i.e., the output of REFER module) as input, and performs visual grounding via bottom-up attention mechanism. We qualitatively and quantitatively evaluate our model on VisDial v1.0 and v0.9 datasets, showing that DAN outperforms the previous state-of-the-art model by a significant margin.
PDF Abstract IJCNLP 2019 PDF IJCNLP 2019 Abstract





 MS COCO
MS COCO
 Visual Question Answering
Visual Question Answering
 VisDial
VisDial

