EasyQuant: Post-training Quantization via Scale Optimization
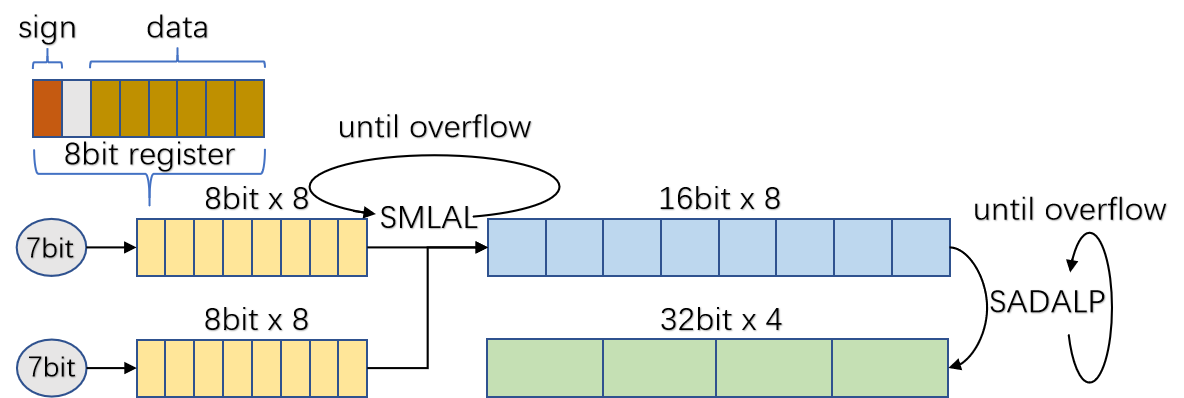
The 8 bits quantization has been widely applied to accelerate network inference in various deep learning applications. There are two kinds of quantization methods, training-based quantization and post-training quantization. Training-based approach suffers from a cumbersome training process, while post-training quantization may lead to unacceptable accuracy drop. In this paper, we present an efficient and simple post-training method via scale optimization, named EasyQuant (EQ),that could obtain comparable accuracy with the training-based method.Specifically, we first alternately optimize scales of weights and activations for all layers target at convolutional outputs to further obtain the high quantization precision. Then, we lower down bit width to INT7 both for weights and activations, and adopt INT16 intermediate storage and integer Winograd convolution implementation to accelerate inference.Experimental results on various computer vision tasks show that EQ outperforms the TensorRT method and can achieve near INT8 accuracy in 7 bits width post-training.
PDF Abstract

 ImageNet
ImageNet
 ssd
ssd
