Efficient conformer: Progressive downsampling and grouped attention for automatic speech recognition
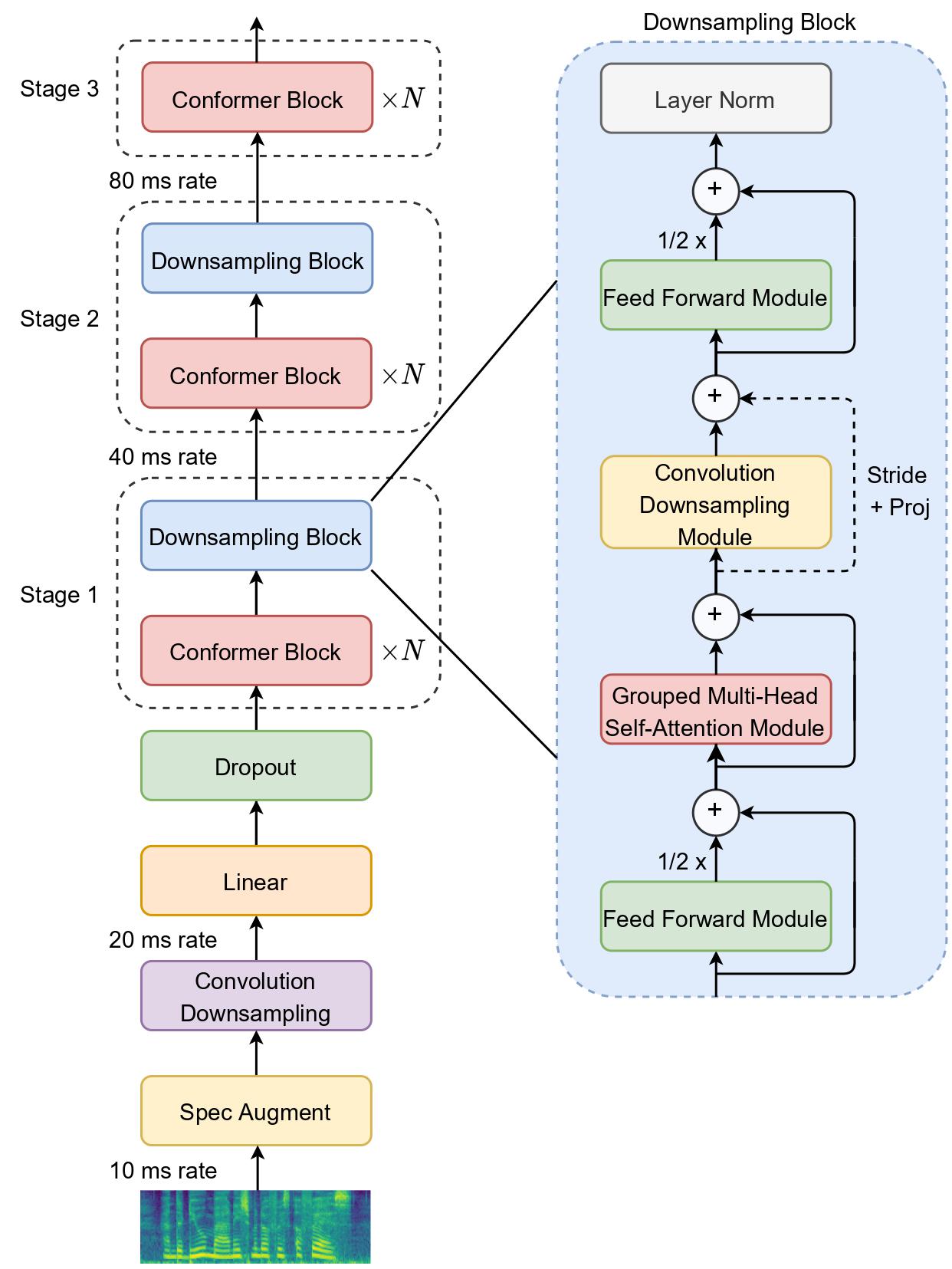
The recently proposed Conformer architecture has shown state-of-the-art performances in Automatic Speech Recognition by combining convolution with attention to model both local and global dependencies. In this paper, we study how to reduce the Conformer architecture complexity with a limited computing budget, leading to a more efficient architecture design that we call Efficient Conformer. We introduce progressive downsampling to the Conformer encoder and propose a novel attention mechanism named grouped attention, allowing us to reduce attention complexity from $O(n^{2}d)$ to $O(n^{2}d / g)$ for sequence length $n$, hidden dimension $d$ and group size parameter $g$. We also experiment the use of strided multi-head self-attention as a global downsampling operation. Our experiments are performed on the LibriSpeech dataset with CTC and RNN-Transducer losses. We show that within the same computing budget, the proposed architecture achieves better performances with faster training and decoding compared to the Conformer. Our 13M parameters CTC model achieves competitive WERs of 3.6%/9.0% without using a language model and 2.7%/6.7% with an external n-gram language model on the test-clean/test-other sets while being 29% faster than our CTC Conformer baseline at inference and 36% faster to train.
PDF Abstract Colab
Colab




 LibriSpeech
LibriSpeech
