Efficient Contextualized Representation: Language Model Pruning for Sequence Labeling
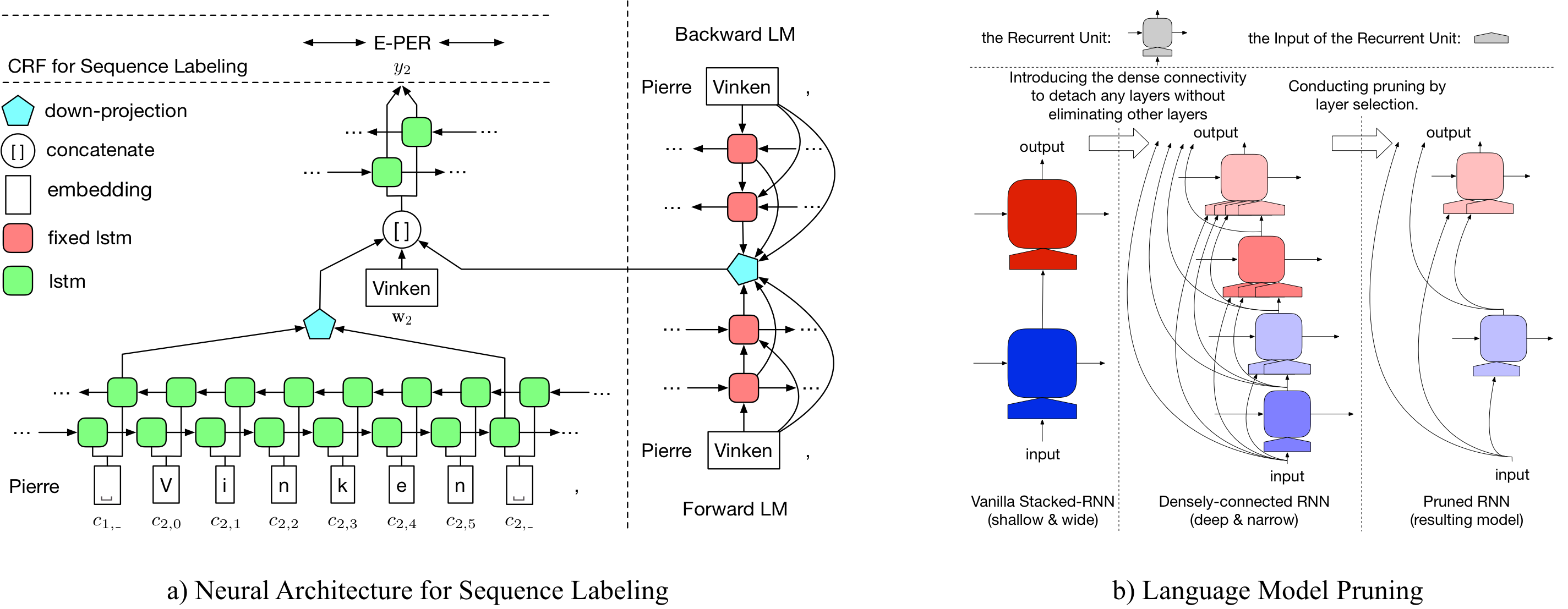
Many efforts have been made to facilitate natural language processing tasks with pre-trained language models (LMs), and brought significant improvements to various applications. To fully leverage the nearly unlimited corpora and capture linguistic information of multifarious levels, large-size LMs are required; but for a specific task, only parts of these information are useful. Such large-sized LMs, even in the inference stage, may cause heavy computation workloads, making them too time-consuming for large-scale applications. Here we propose to compress bulky LMs while preserving useful information with regard to a specific task. As different layers of the model keep different information, we develop a layer selection method for model pruning using sparsity-inducing regularization. By introducing the dense connectivity, we can detach any layer without affecting others, and stretch shallow and wide LMs to be deep and narrow. In model training, LMs are learned with layer-wise dropouts for better robustness. Experiments on two benchmark datasets demonstrate the effectiveness of our method.
PDF Abstract EMNLP 2018 PDF EMNLP 2018 Abstract



