Efficient Process-to-Node Mapping Algorithms for Stencil Computations
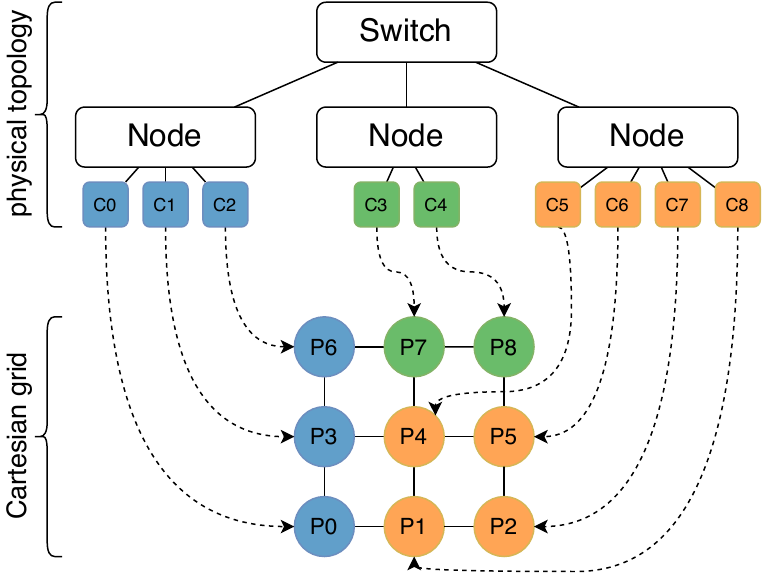
Good process-to-compute-node mappings can be decisive for well performing HPC applications. A special, important class of process-to-node mapping problems is the problem of mapping processes that communicate in a sparse stencil pattern to Cartesian grids. By thoroughly exploiting the inherently present structure in this type of problem, we devise three novel distributed algorithms that are able to handle arbitrary stencil communication patterns effectively. We analyze the expected performance of our algorithms based on an abstract model of inter- and intra-node communication. An extensive experimental evaluation on several HPC machines shows that our algorithms are up to two orders of magnitude faster in running time than a (sequential) high-quality general graph mapping tool, while obtaining similar results in communication performance. Furthermore, our algorithms also achieve significantly better mapping quality compared to previous state-of-the-art Cartesian grid mapping algorithms. This results in up to a threefold performance improvement of an MPI_Neighbor_alltoall exchange operation. Our new algorithms can be used to implement the MPI_Cart_create functionality.
PDF Abstract