EVEREST: Efficient Masked Video Autoencoder by Removing Redundant Spatiotemporal Tokens
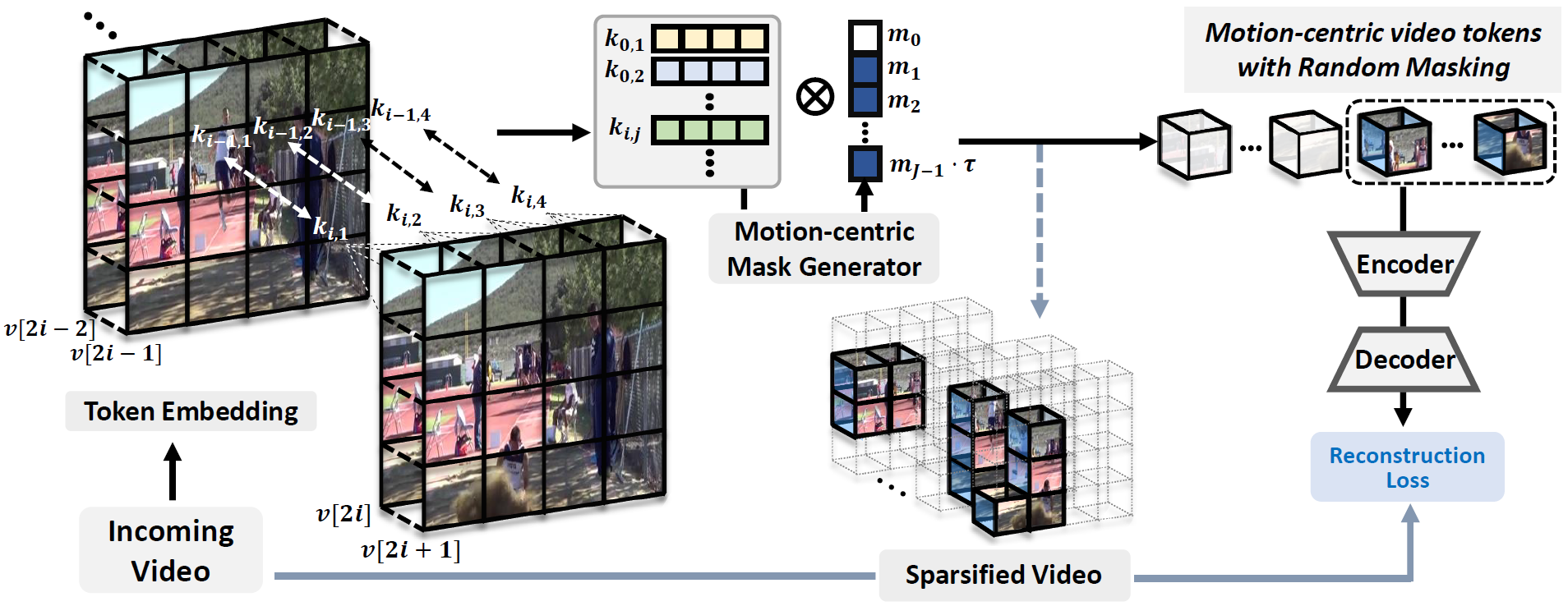
Masked Video Autoencoder (MVA) approaches have demonstrated their potential by significantly outperforming previous video representation learning methods. However, they waste an excessive amount of computations and memory in predicting uninformative tokens/frames due to random masking strategies. (e.g., over 16 nodes with 128 NVIDIA A100 GPUs). To resolve this issue, we exploit the unequal information density among the patches in videos and propose EVEREST, a surprisingly efficient MVA approach for video representation learning that finds tokens containing rich motion features and discards uninformative ones during both pre-training and fine-tuning. We further present an information-intensive frame selection strategy that allows the model to focus on informative and causal frames with minimal redundancy. Our method significantly reduces the computation and memory requirements of MVA, enabling the pre-training and fine-tuning on a single machine with 8 GPUs while achieving comparable performance to computation- and memory-heavy baselines on multiple benchmarks and the uncurated Ego4D dataset. We hope that our work contributes to reducing the barrier to further research on video understanding.
PDF Abstract




 UCF101
UCF101
 HMDB51
HMDB51
 Something-Something V2
Something-Something V2
 Ego4D
Ego4D

