Efficient Visual Pretraining with Contrastive Detection
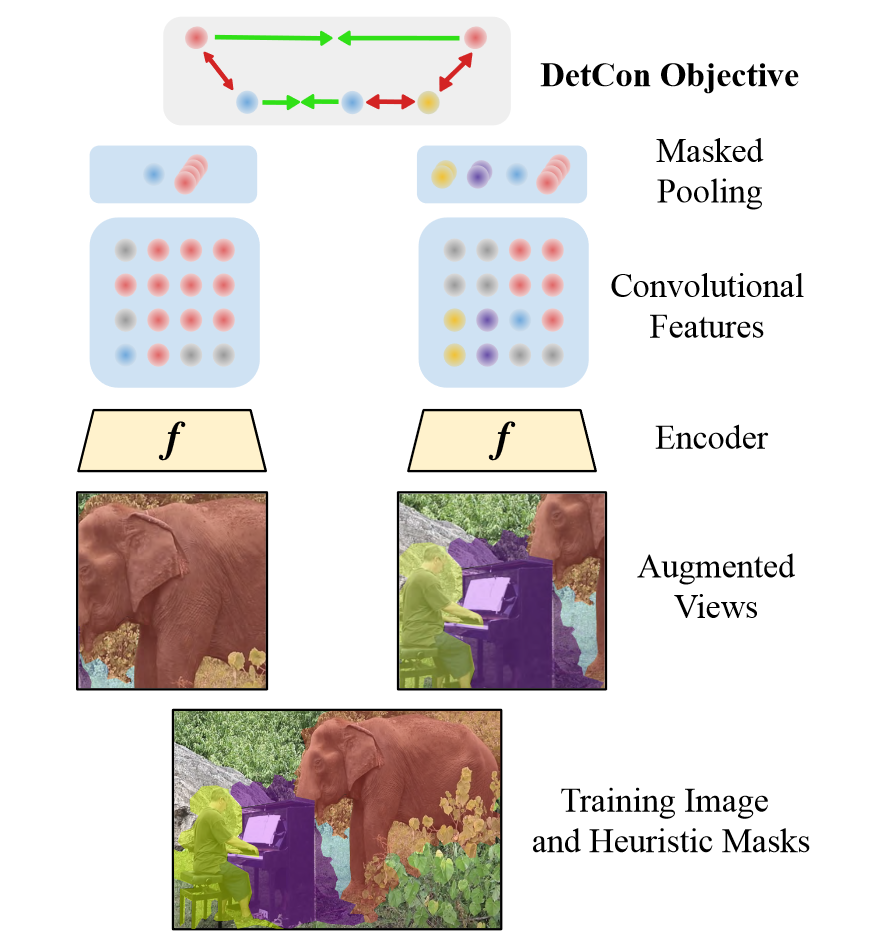
Self-supervised pretraining has been shown to yield powerful representations for transfer learning. These performance gains come at a large computational cost however, with state-of-the-art methods requiring an order of magnitude more computation than supervised pretraining. We tackle this computational bottleneck by introducing a new self-supervised objective, contrastive detection, which tasks representations with identifying object-level features across augmentations. This objective extracts a rich learning signal per image, leading to state-of-the-art transfer accuracy on a variety of downstream tasks, while requiring up to 10x less pretraining. In particular, our strongest ImageNet-pretrained model performs on par with SEER, one of the largest self-supervised systems to date, which uses 1000x more pretraining data. Finally, our objective seamlessly handles pretraining on more complex images such as those in COCO, closing the gap with supervised transfer learning from COCO to PASCAL.
PDF Abstract ICCV 2021 PDF ICCV 2021 AbstractCode
 Colab
Colab




Datasets
 Cityscapes
Cityscapes
Results from the Paper
 Ranked #55 on
Semantic Segmentation
on Cityscapes val
(using extra training data)
Ranked #55 on
Semantic Segmentation
on Cityscapes val
(using extra training data)
